mirror of
https://github.com/OMGeeky/gpt-pilot.git
synced 2026-02-23 15:49:50 +01:00
merge master into debugging_ipc branch
This commit is contained in:
44
.github/workflows/ci.yml
vendored
Normal file
44
.github/workflows/ci.yml
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
name: Test & QA
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
pull_request:
|
||||
branches:
|
||||
- main
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ['3.8', '3.9', '3.10', '3.11']
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install -r requirements.txt
|
||||
|
||||
- name: Lint
|
||||
run: |
|
||||
pip install flake8 ruff
|
||||
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
|
||||
# stop the build if there are Python syntax errors or undefined names
|
||||
ruff --format=github --select=E9,F63,F7,F82 --target-version=py37 .
|
||||
# default set of ruff rules with GitHub Annotations
|
||||
#ruff --format=github --target-version=py37 --ignore=F401,E501 .
|
||||
|
||||
- name: Run tests
|
||||
run: |
|
||||
pip install pytest
|
||||
cd pilot
|
||||
PYTHONPATH=. pytest
|
||||
3
.gitignore
vendored
3
.gitignore
vendored
@@ -167,4 +167,5 @@ cython_debug/
|
||||
/pilot/gpt-pilot
|
||||
|
||||
# workspace
|
||||
workspace
|
||||
workspace
|
||||
pilot-env/
|
||||
|
||||
29
Dockerfile
Normal file
29
Dockerfile
Normal file
@@ -0,0 +1,29 @@
|
||||
FROM python:3
|
||||
|
||||
# Download precompiled ttyd binary from GitHub releases
|
||||
RUN apt-get update && \
|
||||
apt-get install -y wget && \
|
||||
wget https://github.com/tsl0922/ttyd/releases/download/1.6.3/ttyd.x86_64 -O /usr/bin/ttyd && \
|
||||
chmod +x /usr/bin/ttyd && \
|
||||
apt-get remove -y wget && \
|
||||
apt-get autoremove -y && \
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
|
||||
ENV NVM_DIR /root/.nvm
|
||||
|
||||
RUN curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh | bash \
|
||||
&& . "$NVM_DIR/nvm.sh" \
|
||||
&& nvm install node \
|
||||
&& nvm use node
|
||||
|
||||
WORKDIR /usr/src/app
|
||||
COPY . .
|
||||
RUN pip install --no-cache-dir -r requirements.txt
|
||||
RUN python -m venv pilot-env
|
||||
RUN /bin/bash -c "source pilot-env/bin/activate"
|
||||
|
||||
WORKDIR /usr/src/app/pilot
|
||||
RUN pip install -r requirements.txt
|
||||
|
||||
EXPOSE 7681
|
||||
CMD ["ttyd", "bash"]
|
||||
97
README.md
97
README.md
@@ -1,9 +1,31 @@
|
||||
# 🧑✈️ GPT PILOT
|
||||
### GPT Pilot codes the entire app as you oversee the code being written
|
||||
### GPT Pilot helps developers build apps 20x faster
|
||||
|
||||
You specify what kind of an app you want to build. Then, GPT Pilot asks clarifying questions, creates the product and technical requirements, sets up the environment, and **starts coding the app step by step, like in real life while you oversee the development process**. It asks you to review each task it finishes or to help when it gets stuck. This way, GPT Pilot acts as a coder while you are a lead dev who reviews code and helps when needed.
|
||||
|
||||
---
|
||||
|
||||
This is a research project to see how can GPT-4 be utilized to generate fully working, production-ready, apps. **The main idea is that AI can write most of the code for an app (maybe 95%) but for the rest 5%, a developer is and will be needed until we get full AGI**.
|
||||
<!-- TOC -->
|
||||
* [🔌 Requirements](#-requirements)
|
||||
* [🚦How to start using gpt-pilot?](#how-to-start-using-gpt-pilot)
|
||||
* [🐳 How to start gpt-pilot in docker?](#-how-to-start-gpt-pilot-in-docker)
|
||||
* [🧑💻️ Other arguments](#%EF%B8%8F-other-arguments)
|
||||
* [🔎 Examples](#-examples)
|
||||
* [Real-time chat app](#-real-time-chat-app)
|
||||
* [Markdown editor](#-markdown-editor)
|
||||
* [Timer app](#%EF%B8%8F-timer-app)
|
||||
* [🏛 Main pillars of GPT Pilot](#-main-pillars-of-gpt-pilot)
|
||||
* [🏗 How GPT Pilot works?](#-how-gpt-pilot-works)
|
||||
* [🕴How's GPT Pilot different from _Smol developer_ and _GPT engineer_?](#hows-gpt-pilot-different-from-smol-developer-and-gpt-engineer)
|
||||
* [🍻 Contributing](#-contributing)
|
||||
* [🔗 Connect with us](#-connect-with-us)
|
||||
<!-- TOC -->
|
||||
|
||||
---
|
||||
|
||||
The goal of GPT Pilot is to research how much can GPT-4 be utilized to generate fully working, production-ready apps while the developer oversees the implementation.
|
||||
|
||||
**The main idea is that AI can write most of the code for an app (maybe 95%) but for the rest 5%, a developer is and will be needed until we get full AGI**.
|
||||
|
||||
I've broken down the idea behind GPT Pilot and how it works in the following blog posts:
|
||||
|
||||
@@ -15,26 +37,17 @@ I've broken down the idea behind GPT Pilot and how it works in the following blo
|
||||
|
||||
---
|
||||
|
||||
|
||||
<div align="center">
|
||||
|
||||
### **[👉 Examples of apps written by GPT Pilot 👈](#-examples)**
|
||||
|
||||
</div>
|
||||
|
||||
<br>
|
||||
|
||||
https://github.com/Pythagora-io/gpt-pilot/assets/10895136/0495631b-511e-451b-93d5-8a42acf22d3d
|
||||
|
||||
<br>
|
||||
|
||||
## Main pillars of GPT Pilot:
|
||||
1. For AI to create a fully working app, **a developer needs to be involved** in the process of app creation. They need to be able to change the code at any moment and GPT Pilot needs to continue working with those changes (eg. add an API key or fix an issue if an AI gets stuck) <br><br>
|
||||
2. **The app needs to be written step by step as a developer would write it** - Let's say you want to create a simple app and you know everything you need to code and have the entire architecture in your head. Even then, you won't code it out entirely, then run it for the first time and debug all the issues at once. Rather, you will implement something simple, like add routes, run it, see how it works, and then move on to the next task. This way, you can debug issues as they arise. The same should be in the case when AI codes. It will make mistakes for sure so in order for it to have an easier time debugging issues and for the developer to understand what is happening, the AI shouldn't just spit out the entire codebase at once. Rather, the app should be developed step by step just like a developer would code it - eg. setup routes, add database connection, etc. <br><br>
|
||||
3. **The approach needs to be scalable** so that AI can create a production ready app
|
||||
1. **Context rewinding** - for solving each development task, the context size of the first message to the LLM has to be relatively the same. For example, the context size of the first LLM message while implementing development task #5 has to be more or less the same as the first message while developing task #50. Because of this, the conversation needs to be rewound to the first message upon each task. [See the diagram here](https://blogpythagora.files.wordpress.com/2023/08/pythagora-product-development-frame-3-1.jpg?w=1714).
|
||||
2. **Recursive conversations** are LLM conversations that are set up in a way that they can be used “recursively”. For example, if GPT Pilot detects an error, it needs to debug it but let’s say that, during the debugging process, another error happens. Then, GPT Pilot needs to stop debugging the first issue, fix the second one, and then get back to fixing the first issue. This is a very important concept that, I believe, needs to work to make AI build large and scalable apps by itself. It works by rewinding the context and explaining each error in the recursion separately. Once the deepest level error is fixed, we move up in the recursion and continue fixing that error. We do this until the entire recursion is completed.
|
||||
3. **TDD (Test Driven Development)** - for GPT Pilot to be able to scale the codebase, it will need to be able to create new code without breaking previously written code. There is no better way to do this than working with TDD methodology. For each code that GPT Pilot writes, it needs to write tests that check if the code works as intended so that whenever new changes are made, all previous tests can be run.
|
||||
|
||||
The idea is that AI won't be able to (at least in the near future) create apps from scratch without the developer being involved. That's why we created an interactive tool that generates code but also requires the developer to check each step so that they can understand what's going on and so that the AI can have a better overview of the entire codebase.
|
||||
|
||||
Obviously, it still can't create any production-ready app but the general concept of how this could work is there.
|
||||
|
||||
# 🔌 Requirements
|
||||
|
||||
|
||||
@@ -64,6 +77,17 @@ All generated code will be stored in the folder `workspace` inside the folder na
|
||||
**IMPORTANT: To run GPT Pilot, you need to have PostgreSQL set up on your machine**
|
||||
<br>
|
||||
|
||||
## 🐳 How to start gpt-pilot in docker?
|
||||
1. `git clone https://github.com/Pythagora-io/gpt-pilot.git` (clone the repo)
|
||||
2. Update the `docker-compose.yml` environment variables
|
||||
3. run `docker compose build`. this will build a gpt-pilot container for you.
|
||||
4. run `docker compose up`.
|
||||
5. access web terminal on `port 7681`
|
||||
6. `python db_init.py` (initialize the database)
|
||||
7. `python main.py` (start GPT Pilot)
|
||||
|
||||
This will start two containers, one being a new image built by the `Dockerfile` and a postgres database. The new image also has [ttyd](https://github.com/tsl0922/ttyd) installed so you can easily interact with gpt-pilot. Node is also installed on the image and port 3000 is exposed.
|
||||
|
||||
# 🧑💻️ Other arguments
|
||||
- continue working on an existing app
|
||||
```bash
|
||||
@@ -90,34 +114,36 @@ python main.py app_id=<ID_OF_THE_APP> skip_until_dev_step=0
|
||||
|
||||
Here are a couple of example apps GPT Pilot created by itself:
|
||||
|
||||
### Real-time chat app
|
||||
### 📱 Real-time chat app
|
||||
- 💬 Prompt: `A simple chat app with real time communication`
|
||||
- ▶️ [Video of the app creation process](https://youtu.be/bUj9DbMRYhA)
|
||||
- 💻️ [GitHub repo](https://github.com/Pythagora-io/gpt-pilot-chat-app-demo)
|
||||
|
||||
<p align="left">
|
||||
<img src="https://github.com/Pythagora-io/gpt-pilot/assets/10895136/85bc705c-be88-4ca1-9a3b-033700b97a22" alt="gpt-pilot demo chat app" width="500px"/>
|
||||
</p>
|
||||
|
||||
|
||||
### Markdown editor
|
||||
### 📝 Markdown editor
|
||||
- 💬 Prompt: `Build a simple markdown editor using HTML, CSS, and JavaScript. Allow users to input markdown text and display the formatted output in real-time.`
|
||||
- ▶️ [Video of the app creation process](https://youtu.be/uZeA1iX9dgg)
|
||||
- 💻️ [GitHub repo](https://github.com/Pythagora-io/gpt-pilot-demo-markdown-editor.git)
|
||||
|
||||
<p align="left">
|
||||
<img src="https://github.com/Pythagora-io/gpt-pilot/assets/10895136/dbe1ccc3-b126-4df0-bddb-a524d6a386a8" alt="gpt-pilot demo markdown editor" width="500px"/>
|
||||
</p>
|
||||
|
||||
|
||||
### Timer app
|
||||
### ⏱️ Timer app
|
||||
- 💬 Prompt: `Create a simple timer app using HTML, CSS, and JavaScript that allows users to set a countdown timer and receive an alert when the time is up.`
|
||||
- ▶️ [Video of the app creation process](https://youtu.be/CMN3W18zfiE)
|
||||
- 💻️ [GitHub repo](https://github.com/Pythagora-io/gpt-pilot-timer-app-demo)
|
||||
|
||||
<p align="left">
|
||||
<img src="https://github.com/Pythagora-io/gpt-pilot/assets/10895136/93bed40b-b769-4c8b-b16d-b80fb6fc73e0" alt="gpt-pilot demo markdown editor" width="500px"/>
|
||||
</p>
|
||||
<br>
|
||||
|
||||
# 🏛 Main pillars of GPT Pilot:
|
||||
1. For AI to create a fully working app, **a developer needs to be involved** in the process of app creation. They need to be able to change the code at any moment and GPT Pilot needs to continue working with those changes (eg. add an API key or fix an issue if an AI gets stuck) <br><br>
|
||||
2. **The app needs to be written step by step as a developer would write it** - Let's say you want to create a simple app and you know everything you need to code and have the entire architecture in your head. Even then, you won't code it out entirely, then run it for the first time and debug all the issues at once. Rather, you will implement something simple, like add routes, run it, see how it works, and then move on to the next task. This way, you can debug issues as they arise. The same should be in the case when AI codes. It will make mistakes for sure so in order for it to have an easier time debugging issues and for the developer to understand what is happening, the AI shouldn't just spit out the entire codebase at once. Rather, the app should be developed step by step just like a developer would code it - eg. setup routes, add database connection, etc. <br><br>
|
||||
3. **The approach needs to be scalable** so that AI can create a production ready app
|
||||
1. **Context rewinding** - for solving each development task, the context size of the first message to the LLM has to be relatively the same. For example, the context size of the first LLM message while implementing development task #5 has to be more or less the same as the first message while developing task #50. Because of this, the conversation needs to be rewound to the first message upon each task. [See the diagram here](https://blogpythagora.files.wordpress.com/2023/08/pythagora-product-development-frame-3-1.jpg?w=1714).
|
||||
2. **Recursive conversations** are LLM conversations that are set up in a way that they can be used “recursively”. For example, if GPT Pilot detects an error, it needs to debug it but let’s say that, during the debugging process, another error happens. Then, GPT Pilot needs to stop debugging the first issue, fix the second one, and then get back to fixing the first issue. This is a very important concept that, I believe, needs to work to make AI build large and scalable apps by itself. It works by rewinding the context and explaining each error in the recursion separately. Once the deepest level error is fixed, we move up in the recursion and continue fixing that error. We do this until the entire recursion is completed.
|
||||
3. **TDD (Test Driven Development)** - for GPT Pilot to be able to scale the codebase, it will need to be able to create new code without breaking previously written code. There is no better way to do this than working with TDD methodology. For each code that GPT Pilot writes, it needs to write tests that check if the code works as intended so that whenever new changes are made, all previous tests can be run.
|
||||
|
||||
The idea is that AI won't be able to (at least in the near future) create apps from scratch without the developer being involved. That's why we created an interactive tool that generates code but also requires the developer to check each step so that they can understand what's going on and so that the AI can have a better overview of the entire codebase.
|
||||
|
||||
Obviously, it still can't create any production-ready app but the general concept of how this could work is there.
|
||||
|
||||
# 🏗 How GPT Pilot works?
|
||||
Here are the steps GPT Pilot takes to create an app:
|
||||
@@ -133,16 +159,15 @@ Here are the steps GPT Pilot takes to create an app:
|
||||
7. **Developer agent** takes each task and writes up what needs to be done to implement it. The description is in human readable form.
|
||||
8. Finally, **Code Monkey agent** takes the Developer's description and the currently implement file and implements the changes into it. We realized this works much better than giving it to Developer right away to implement changes.
|
||||
|
||||

|
||||
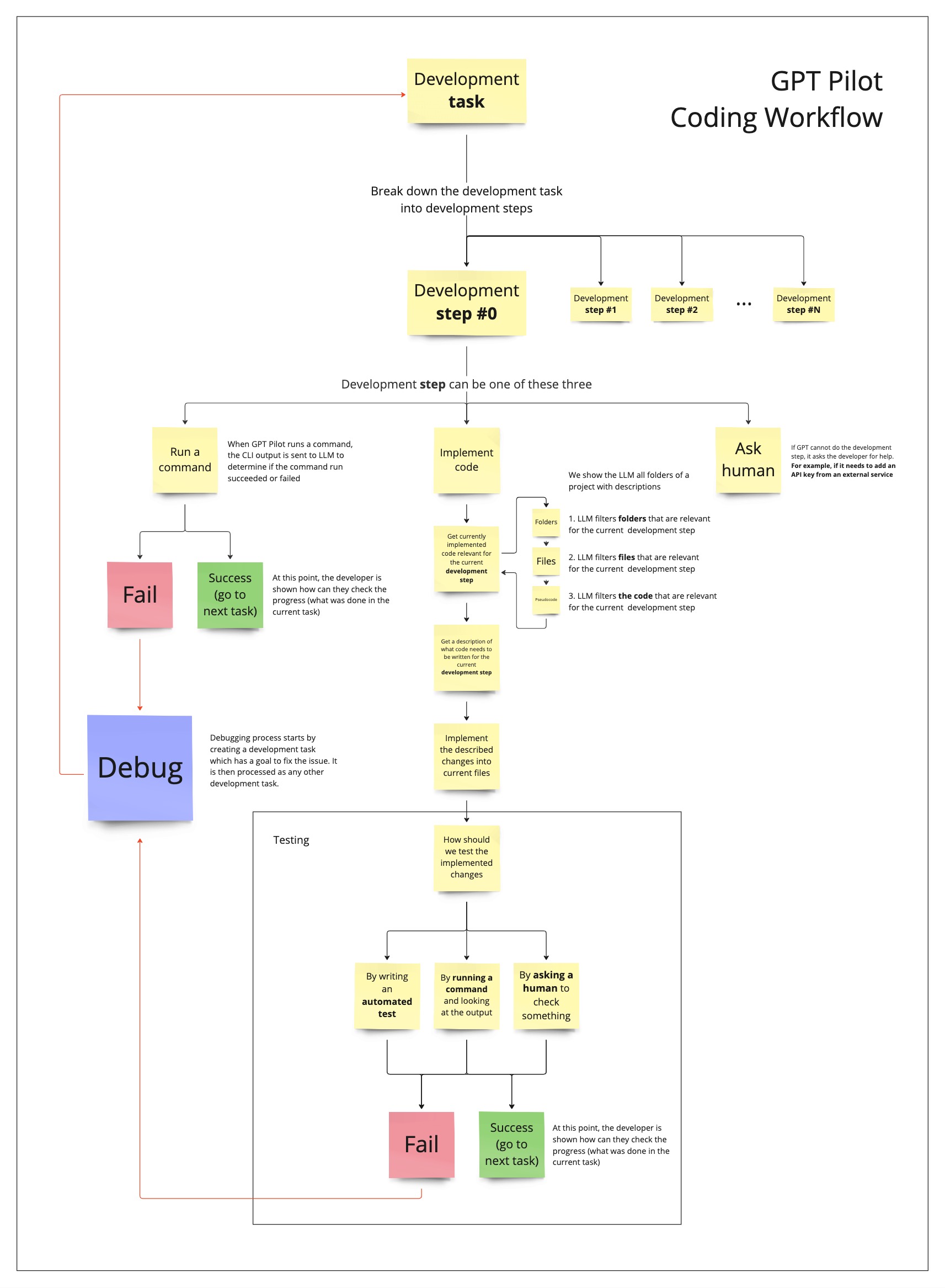
|
||||
|
||||
|
||||
<br>
|
||||
|
||||
# 🕴How's GPT Pilot different from _Smol developer_ and _GPT engineer_?
|
||||
- **Human developer is involved throughout the process** - I don't think that AI can (at least in the near future) create apps without a developer being involved. Also, I think it's hard for a developer to get into a big codebase and try debugging it. That's why my idea was for AI to develop the app step by step where each step is reviewed by the developer. If you want to change some code yourself, you can just change it and GPT Pilot will continue developing on top of those changes.
|
||||
- **GPT Pilot works with the developer to create fully working production-ready app** - I don't think that AI can (at least in the near future) create apps without a developer being involved. So, **GPT Pilot codes the app step by step** just like a developer would in real life. This way, it can debug issues as they arise throughout the development process. If it gets stuck, you, the developer in charge, can review the code and fix the issue. Other similar tools give you the entire codebase at once - this way, bugs are much harder to fix both for AI and for you as a developer.
|
||||
<br><br>
|
||||
- **Continuous development loops** - The goal behind this project was to see how we can create recursive conversations with GPT so that it can debug any issue and implement any feature. For example, after the app is generated, you can always add more instructions about what you want to implement or debug. I wanted to see if this can be so flexible that, regardless of the app's size, it can just iterate and build bigger and bigger apps
|
||||
<br><br>
|
||||
- **Auto debugging** - when it detects an error, it debugs it by itself. I still haven't implemented writing automated tests which should make this fully autonomous but for now, you can input the error that's happening (eg. within a UI) and GPT Pilot will debug it from there. The plan is to make it write automated tests in Cypress as well so that it can test it by itself and debug without the developer's explanation.
|
||||
- **Works at scale** - GPT Pilot isn't meant to create simple apps but rather so it can work at any scale. It has mechanisms that filter out the code so in each LLM conversation, it doesn't need to store the entire codebase in context but it shows the LLM only the code that is relevant for the current task it's working on. Once an app is finished, you can always continue working on it by writing instructions on what feature you want to add.
|
||||
|
||||
# 🍻 Contributing
|
||||
If you are interested in contributing to GPT Pilot, I would be more than happy to have you on board but also help you get started. Feel free to ping [zvonimir@pythagora.ai](mailto:zvonimir@pythagora.ai) and I'll help you get started.
|
||||
@@ -156,7 +181,7 @@ Other than the research, GPT Pilot needs to be debugged to work in different sce
|
||||
# 🔗 Connect with us
|
||||
🌟 As an open source tool, it would mean the world to us if you starred the GPT-pilot repo 🌟
|
||||
|
||||
💬 Join [the Discord server](https://discord.gg/FWnRZdCb) to get in touch.
|
||||
💬 Join [the Discord server](https://discord.gg/HaqXugmxr9) to get in touch.
|
||||
<br><br>
|
||||
<br><br>
|
||||
|
||||
|
||||
41
docker-compose.yml
Normal file
41
docker-compose.yml
Normal file
@@ -0,0 +1,41 @@
|
||||
version: '3'
|
||||
services:
|
||||
gpt-pilot:
|
||||
environment:
|
||||
#OPENAI or AZURE
|
||||
- ENDPOINT=OPENAI
|
||||
- OPENAI_API_KEY=
|
||||
# - AZURE_API_KEY=
|
||||
# - AZURE_ENDPOINT=
|
||||
#In case of Azure endpoint, change this to your deployed model name
|
||||
- MODEL_NAME=gpt-4
|
||||
- MAX_TOKENS=8192
|
||||
- DATABASE_TYPE=postgres
|
||||
- DB_NAME=pilot
|
||||
- DB_HOST=postgres
|
||||
- DB_PORT=5432
|
||||
- DB_USER=pilot
|
||||
- DB_PASSWORD=pilot
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile
|
||||
ports:
|
||||
- "7681:7681"
|
||||
- "3000:3000"
|
||||
depends_on:
|
||||
postgres:
|
||||
condition: service_healthy
|
||||
postgres:
|
||||
image: postgres
|
||||
restart: always
|
||||
environment:
|
||||
POSTGRES_USER: pilot
|
||||
POSTGRES_PASSWORD: pilot
|
||||
POSTGRES_DB: pilot
|
||||
ports:
|
||||
- "5432:5432"
|
||||
healthcheck:
|
||||
test: ["CMD-SHELL", "pg_isready -U pilot"]
|
||||
interval: 30s
|
||||
timeout: 10s
|
||||
retries: 3
|
||||
@@ -1,13 +1,25 @@
|
||||
#OPENAI or AZURE
|
||||
# OPENAI or AZURE or OPENROUTER
|
||||
ENDPOINT=OPENAI
|
||||
|
||||
OPENAI_ENDPOINT=
|
||||
OPENAI_API_KEY=
|
||||
|
||||
AZURE_API_KEY=
|
||||
AZURE_ENDPOINT=
|
||||
#In case of Azure endpoint, change this to your deployed model name
|
||||
|
||||
OPENROUTER_API_KEY=
|
||||
OPENROUTER_ENDPOINT=https://openrouter.ai/api/v1/chat/completions
|
||||
|
||||
# In case of Azure/OpenRouter endpoint, change this to your deployed model name
|
||||
MODEL_NAME=gpt-4
|
||||
# MODEL_NAME=openai/gpt-3.5-turbo-16k
|
||||
MAX_TOKENS=8192
|
||||
|
||||
# Database
|
||||
# DATABASE_TYPE=postgres
|
||||
|
||||
DB_NAME=gpt-pilot
|
||||
DB_HOST=localhost
|
||||
DB_PORT=5432
|
||||
DB_USER=admin
|
||||
DB_PASSWORD=admin
|
||||
DB_HOST=
|
||||
DB_PORT=
|
||||
DB_USER=
|
||||
DB_PASSWORD=
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
APP_TYPES = ['Web App', 'Script', 'Mobile App (unavailable)', 'Chrome Extension (unavailable)']
|
||||
APP_TYPES = ['Web App', 'Script', 'Mobile App', 'Chrome Extension']
|
||||
ROLES = {
|
||||
'product_owner': ['project_description', 'user_stories', 'user_tasks'],
|
||||
'architect': ['architecture'],
|
||||
|
||||
@@ -1,5 +1,5 @@
|
||||
import os
|
||||
MAX_GPT_MODEL_TOKENS = int(os.getenv('MAX_TOKENS'))
|
||||
MAX_GPT_MODEL_TOKENS = int(os.getenv('MAX_TOKENS', 8192))
|
||||
MIN_TOKENS_FOR_GPT_RESPONSE = 600
|
||||
MAX_QUESTIONS = 5
|
||||
END_RESPONSE = "EVERYTHING_CLEAR"
|
||||
@@ -4,10 +4,10 @@ from fabulous.color import yellow, red
|
||||
from functools import reduce
|
||||
import operator
|
||||
import psycopg2
|
||||
from const.common import PROMPT_DATA_TO_IGNORE
|
||||
from logger.logger import logger
|
||||
from psycopg2.extensions import quote_ident
|
||||
|
||||
from const.common import PROMPT_DATA_TO_IGNORE
|
||||
from logger.logger import logger
|
||||
from utils.utils import hash_data
|
||||
from database.config import DB_NAME, DB_HOST, DB_PORT, DB_USER, DB_PASSWORD, DATABASE_TYPE
|
||||
from database.models.components.base_models import database
|
||||
@@ -23,6 +23,7 @@ from database.models.environment_setup import EnvironmentSetup
|
||||
from database.models.development import Development
|
||||
from database.models.file_snapshot import FileSnapshot
|
||||
from database.models.command_runs import CommandRuns
|
||||
from database.models.user_apps import UserApps
|
||||
from database.models.user_inputs import UserInputs
|
||||
from database.models.files import File
|
||||
|
||||
@@ -106,6 +107,16 @@ def save_app(args):
|
||||
return app
|
||||
|
||||
|
||||
def save_user_app(user_id, app_id, workspace):
|
||||
try:
|
||||
user_app = UserApps.get((UserApps.user == user_id) & (UserApps.app == app_id))
|
||||
user_app.workspace = workspace
|
||||
user_app.save()
|
||||
except DoesNotExist:
|
||||
user_app = UserApps.create(user=user_id, app=app_id, workspace=workspace)
|
||||
|
||||
return user_app
|
||||
|
||||
def save_progress(app_id, step, data):
|
||||
progress_table_map = {
|
||||
'project_description': ProjectDescription,
|
||||
@@ -146,6 +157,14 @@ def get_app(app_id):
|
||||
raise ValueError(f"No app with id: {app_id}")
|
||||
|
||||
|
||||
def get_app_by_user_workspace(user_id, workspace):
|
||||
try:
|
||||
user_app = UserApps.get((UserApps.user == user_id) & (UserApps.workspace == workspace))
|
||||
return user_app.app
|
||||
except DoesNotExist:
|
||||
return None
|
||||
|
||||
|
||||
def get_progress_steps(app_id, step=None):
|
||||
progress_table_map = {
|
||||
'project_description': ProjectDescription,
|
||||
@@ -230,10 +249,8 @@ def save_development_step(project, prompt_path, prompt_data, messages, llm_respo
|
||||
development_step = hash_and_save_step(DevelopmentSteps, project.args['app_id'], unique_data, data_fields, "Saved Development Step")
|
||||
project.checkpoints['last_development_step'] = development_step
|
||||
|
||||
|
||||
project.save_files_snapshot(development_step.id)
|
||||
|
||||
|
||||
return development_step
|
||||
|
||||
|
||||
@@ -327,7 +344,7 @@ def get_all_connected_steps(step, previous_step_field_name):
|
||||
|
||||
|
||||
def delete_all_app_development_data(app):
|
||||
models = [DevelopmentSteps, CommandRuns, UserInputs, File, FileSnapshot]
|
||||
models = [DevelopmentSteps, CommandRuns, UserInputs, UserApps, File, FileSnapshot]
|
||||
for model in models:
|
||||
model.delete().where(model.app == app).execute()
|
||||
|
||||
@@ -372,6 +389,7 @@ def create_tables():
|
||||
Development,
|
||||
FileSnapshot,
|
||||
CommandRuns,
|
||||
UserApps,
|
||||
UserInputs,
|
||||
File,
|
||||
])
|
||||
@@ -392,10 +410,11 @@ def drop_tables():
|
||||
Development,
|
||||
FileSnapshot,
|
||||
CommandRuns,
|
||||
UserApps,
|
||||
UserInputs,
|
||||
File,
|
||||
]:
|
||||
if DATABASE_TYPE == "postgresql":
|
||||
if DATABASE_TYPE == "postgres":
|
||||
sql = f'DROP TABLE IF EXISTS "{table._meta.table_name}" CASCADE'
|
||||
elif DATABASE_TYPE == "sqlite":
|
||||
sql = f'DROP TABLE IF EXISTS "{table._meta.table_name}"'
|
||||
@@ -441,7 +460,7 @@ def create_database():
|
||||
|
||||
def tables_exist():
|
||||
tables = [User, App, ProjectDescription, UserStories, UserTasks, Architecture, DevelopmentPlanning,
|
||||
DevelopmentSteps, EnvironmentSetup, Development, FileSnapshot, CommandRuns, UserInputs, File]
|
||||
DevelopmentSteps, EnvironmentSetup, Development, FileSnapshot, CommandRuns, UserApps, UserInputs, File]
|
||||
|
||||
if DATABASE_TYPE == "postgres":
|
||||
for table in tables:
|
||||
|
||||
@@ -12,4 +12,4 @@ class Architecture(ProgressStep):
|
||||
architecture = JSONField() # Custom JSON field for SQLite
|
||||
|
||||
class Meta:
|
||||
db_table = 'architecture'
|
||||
table_name = 'architecture'
|
||||
|
||||
@@ -13,7 +13,7 @@ class CommandRuns(BaseModel):
|
||||
high_level_step = CharField(null=True)
|
||||
|
||||
class Meta:
|
||||
db_table = 'command_runs'
|
||||
table_name = 'command_runs'
|
||||
indexes = (
|
||||
(('app', 'previous_step', 'high_level_step'), True),
|
||||
)
|
||||
@@ -5,4 +5,4 @@ from database.models.components.progress_step import ProgressStep
|
||||
|
||||
class Development(ProgressStep):
|
||||
class Meta:
|
||||
db_table = 'development'
|
||||
table_name = 'development'
|
||||
|
||||
@@ -12,4 +12,4 @@ class DevelopmentPlanning(ProgressStep):
|
||||
development_plan = JSONField() # Custom JSON field for SQLite
|
||||
|
||||
class Meta:
|
||||
db_table = 'development_planning'
|
||||
table_name = 'development_planning'
|
||||
|
||||
@@ -25,7 +25,7 @@ class DevelopmentSteps(BaseModel):
|
||||
high_level_step = CharField(null=True)
|
||||
|
||||
class Meta:
|
||||
db_table = 'development_steps'
|
||||
table_name = 'development_steps'
|
||||
indexes = (
|
||||
(('app', 'previous_step', 'high_level_step'), True),
|
||||
)
|
||||
|
||||
@@ -3,4 +3,4 @@ from database.models.components.progress_step import ProgressStep
|
||||
|
||||
class EnvironmentSetup(ProgressStep):
|
||||
class Meta:
|
||||
db_table = 'environment_setup'
|
||||
table_name = 'environment_setup'
|
||||
|
||||
@@ -12,7 +12,7 @@ class FileSnapshot(BaseModel):
|
||||
content = TextField()
|
||||
|
||||
class Meta:
|
||||
db_table = 'file_snapshot'
|
||||
table_name = 'file_snapshot'
|
||||
indexes = (
|
||||
(('development_step', 'file'), True),
|
||||
)
|
||||
@@ -7,4 +7,4 @@ class ProjectDescription(ProgressStep):
|
||||
summary = TextField()
|
||||
|
||||
class Meta:
|
||||
db_table = 'project_description'
|
||||
table_name = 'project_description'
|
||||
|
||||
18
pilot/database/models/user_apps.py
Normal file
18
pilot/database/models/user_apps.py
Normal file
@@ -0,0 +1,18 @@
|
||||
from peewee import *
|
||||
|
||||
from database.models.components.base_models import BaseModel
|
||||
from database.models.app import App
|
||||
from database.models.user import User
|
||||
|
||||
|
||||
class UserApps(BaseModel):
|
||||
id = AutoField()
|
||||
app = ForeignKeyField(App, on_delete='CASCADE')
|
||||
user = ForeignKeyField(User, on_delete='CASCADE')
|
||||
workspace = CharField(null=True)
|
||||
|
||||
class Meta:
|
||||
table_name = 'user_apps'
|
||||
indexes = (
|
||||
(('app', 'user'), True),
|
||||
)
|
||||
@@ -13,7 +13,7 @@ class UserInputs(BaseModel):
|
||||
high_level_step = CharField(null=True)
|
||||
|
||||
class Meta:
|
||||
db_table = 'user_inputs'
|
||||
table_name = 'user_inputs'
|
||||
indexes = (
|
||||
(('app', 'previous_step', 'high_level_step'), True),
|
||||
)
|
||||
@@ -11,4 +11,4 @@ class UserStories(ProgressStep):
|
||||
else:
|
||||
user_stories = JSONField() # Custom JSON field for SQLite
|
||||
class Meta:
|
||||
db_table = 'user_stories'
|
||||
table_name = 'user_stories'
|
||||
|
||||
@@ -12,4 +12,4 @@ class UserTasks(ProgressStep):
|
||||
user_tasks = JSONField() # Custom JSON field for SQLite
|
||||
|
||||
class Meta:
|
||||
db_table = 'user_tasks'
|
||||
table_name = 'user_tasks'
|
||||
|
||||
@@ -47,9 +47,6 @@ class AgentConvo:
|
||||
# craft message
|
||||
self.construct_and_add_message_from_prompt(prompt_path, prompt_data)
|
||||
|
||||
if function_calls is not None and 'function_calls' in function_calls:
|
||||
self.messages[-1]['content'] += '\nMAKE SURE THAT YOU RESPOND WITH A CORRECT JSON FORMAT!!!'
|
||||
|
||||
# check if we already have the LLM response saved
|
||||
if self.agent.__class__.__name__ == 'Developer':
|
||||
self.agent.project.llm_req_num += 1
|
||||
|
||||
@@ -1,12 +1,8 @@
|
||||
import json
|
||||
import os
|
||||
import time
|
||||
|
||||
from fabulous.color import bold, green, yellow, cyan, white
|
||||
from const.common import IGNORE_FOLDERS, STEPS
|
||||
from database.models.app import App
|
||||
from database.database import get_app, delete_unconnected_steps_from, delete_all_app_development_data
|
||||
from helpers.ipc import IPCClient
|
||||
from database.database import delete_unconnected_steps_from, delete_all_app_development_data
|
||||
from const.ipc import MESSAGE_TYPE
|
||||
from helpers.exceptions.TokenLimitError import TokenLimitError
|
||||
from utils.questionary import styled_text
|
||||
@@ -20,7 +16,6 @@ from helpers.agents.ProductOwner import ProductOwner
|
||||
from database.models.development_steps import DevelopmentSteps
|
||||
from database.models.file_snapshot import FileSnapshot
|
||||
from database.models.files import File
|
||||
from utils.files import get_parent_folder
|
||||
|
||||
|
||||
class Project:
|
||||
@@ -30,7 +25,7 @@ class Project:
|
||||
Initialize a project.
|
||||
|
||||
Args:
|
||||
args (dict): Project arguments.
|
||||
args (dict): Project arguments - app_id, (app_type, name), user_id, email, password, step
|
||||
name (str, optional): Project name. Default is None.
|
||||
description (str, optional): Project description. Default is None.
|
||||
user_stories (list, optional): List of user stories. Default is None.
|
||||
@@ -137,7 +132,7 @@ class Project:
|
||||
print(json.dumps({
|
||||
"project_stage": "environment_setup"
|
||||
}), type='info')
|
||||
self.developer.set_up_environment();
|
||||
self.developer.set_up_environment()
|
||||
|
||||
print(json.dumps({
|
||||
"project_stage": "coding"
|
||||
@@ -221,7 +216,7 @@ class Project:
|
||||
Save a file.
|
||||
|
||||
Args:
|
||||
data (dict): File data.
|
||||
data: { name: 'hello.py', path: 'path/to/hello.py', content: 'print("Hello!")' }
|
||||
"""
|
||||
# TODO fix this in prompts
|
||||
if 'path' not in data:
|
||||
|
||||
@@ -4,12 +4,14 @@ import json
|
||||
from fabulous.color import green, bold
|
||||
from const.function_calls import ARCHITECTURE
|
||||
|
||||
from utils.utils import execute_step, find_role_from_step, generate_app_data
|
||||
from utils.utils import should_execute_step, find_role_from_step, generate_app_data
|
||||
from database.database import save_progress, get_progress_steps
|
||||
from logger.logger import logger
|
||||
from prompts.prompts import get_additional_info_from_user
|
||||
from helpers.AgentConvo import AgentConvo
|
||||
|
||||
ARCHITECTURE_STEP = 'architecture'
|
||||
|
||||
|
||||
class Architect(Agent):
|
||||
def __init__(self, project):
|
||||
@@ -17,12 +19,11 @@ class Architect(Agent):
|
||||
self.convo_architecture = None
|
||||
|
||||
def get_architecture(self):
|
||||
self.project.current_step = 'architecture'
|
||||
self.convo_architecture = AgentConvo(self)
|
||||
self.project.current_step = ARCHITECTURE_STEP
|
||||
|
||||
# If this app_id already did this step, just get all data from DB and don't ask user again
|
||||
step = get_progress_steps(self.project.args['app_id'], self.project.current_step)
|
||||
if step and not execute_step(self.project.args['step'], self.project.current_step):
|
||||
step = get_progress_steps(self.project.args['app_id'], ARCHITECTURE_STEP)
|
||||
if step and not should_execute_step(self.project.args['step'], ARCHITECTURE_STEP):
|
||||
step_already_finished(self.project.args, step)
|
||||
return step['architecture']
|
||||
|
||||
@@ -30,6 +31,7 @@ class Architect(Agent):
|
||||
print(green(bold(f"Planning project architecture...\n")))
|
||||
logger.info(f"Planning project architecture...")
|
||||
|
||||
self.convo_architecture = AgentConvo(self)
|
||||
architecture = self.convo_architecture.send_message('architecture/technologies.prompt',
|
||||
{'name': self.project.args['name'],
|
||||
'prompt': self.project.project_description,
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
import json
|
||||
import uuid
|
||||
from fabulous.color import yellow, green, red, bold, blue, white
|
||||
from helpers.exceptions.TokenLimitError import TokenLimitError
|
||||
@@ -6,18 +5,18 @@ from const.code_execution import MAX_COMMAND_DEBUG_TRIES
|
||||
from helpers.exceptions.TooDeepRecursionError import TooDeepRecursionError
|
||||
from helpers.Debugger import Debugger
|
||||
from utils.questionary import styled_text
|
||||
from helpers.files import update_file
|
||||
from utils.utils import step_already_finished
|
||||
from helpers.agents.CodeMonkey import CodeMonkey
|
||||
from logger.logger import logger
|
||||
from helpers.Agent import Agent
|
||||
from helpers.AgentConvo import AgentConvo
|
||||
from utils.utils import execute_step, array_of_objects_to_string, generate_app_data
|
||||
from helpers.cli import build_directory_tree, run_command_until_success, execute_command_and_check_cli_response
|
||||
from const.function_calls import FILTER_OS_TECHNOLOGIES, DEVELOPMENT_PLAN, EXECUTE_COMMANDS, GET_TEST_TYPE, DEV_TASKS_BREAKDOWN, IMPLEMENT_TASK
|
||||
from database.database import save_progress, get_progress_steps, save_file_description
|
||||
from utils.utils import should_execute_step, array_of_objects_to_string, generate_app_data
|
||||
from helpers.cli import run_command_until_success, execute_command_and_check_cli_response, debug
|
||||
from const.function_calls import FILTER_OS_TECHNOLOGIES, EXECUTE_COMMANDS, GET_TEST_TYPE, IMPLEMENT_TASK
|
||||
from database.database import save_progress, get_progress_steps
|
||||
from utils.utils import get_os_info
|
||||
from helpers.cli import execute_command
|
||||
|
||||
ENVIRONMENT_SETUP_STEP = 'environment_setup'
|
||||
|
||||
class Developer(Agent):
|
||||
def __init__(self, project):
|
||||
@@ -48,6 +47,7 @@ class Developer(Agent):
|
||||
convo_dev_task = AgentConvo(self)
|
||||
task_description = convo_dev_task.send_message('development/task/breakdown.prompt', {
|
||||
"name": self.project.args['name'],
|
||||
"app_type": self.project.args['app_type'],
|
||||
"app_summary": self.project.project_description,
|
||||
"clarification": [],
|
||||
"user_stories": self.project.user_stories,
|
||||
@@ -273,6 +273,7 @@ class Developer(Agent):
|
||||
iteration_convo = AgentConvo(self)
|
||||
iteration_convo.send_message('development/iteration.prompt', {
|
||||
"name": self.project.args['name'],
|
||||
"app_type": self.project.args['app_type'],
|
||||
"app_summary": self.project.project_description,
|
||||
"clarification": [],
|
||||
"user_stories": self.project.user_stories,
|
||||
@@ -293,12 +294,12 @@ class Developer(Agent):
|
||||
|
||||
|
||||
def set_up_environment(self):
|
||||
self.project.current_step = 'environment_setup'
|
||||
self.project.current_step = ENVIRONMENT_SETUP_STEP
|
||||
self.convo_os_specific_tech = AgentConvo(self)
|
||||
|
||||
# If this app_id already did this step, just get all data from DB and don't ask user again
|
||||
step = get_progress_steps(self.project.args['app_id'], self.project.current_step)
|
||||
if step and not execute_step(self.project.args['step'], self.project.current_step):
|
||||
step = get_progress_steps(self.project.args['app_id'], ENVIRONMENT_SETUP_STEP)
|
||||
if step and not should_execute_step(self.project.args['step'], ENVIRONMENT_SETUP_STEP):
|
||||
step_already_finished(self.project.args, step)
|
||||
return
|
||||
|
||||
@@ -306,7 +307,7 @@ class Developer(Agent):
|
||||
while user_input.lower() != 'done':
|
||||
user_input = styled_text(self.project, 'Please set up your local environment so that the technologies above can be utilized. When you\'re done, write "DONE"')
|
||||
save_progress(self.project.args['app_id'], self.project.current_step, {
|
||||
"os_specific_techologies": [], "newly_installed_technologies": [], "app_data": generate_app_data(self.project.args)
|
||||
"os_specific_technologies": [], "newly_installed_technologies": [], "app_data": generate_app_data(self.project.args)
|
||||
})
|
||||
return
|
||||
# ENVIRONMENT SETUP
|
||||
@@ -314,11 +315,16 @@ class Developer(Agent):
|
||||
logger.info(f"Setting up the environment...")
|
||||
|
||||
os_info = get_os_info()
|
||||
os_specific_techologies = self.convo_os_specific_tech.send_message('development/env_setup/specs.prompt',
|
||||
{ "name": self.project.args['name'], "os_info": os_info, "technologies": self.project.architecture }, FILTER_OS_TECHNOLOGIES)
|
||||
os_specific_technologies = self.convo_os_specific_tech.send_message('development/env_setup/specs.prompt',
|
||||
{
|
||||
"name": self.project.args['name'],
|
||||
"app_type": self.project.args['app_type'],
|
||||
"os_info": os_info,
|
||||
"technologies": self.project.architecture
|
||||
}, FILTER_OS_TECHNOLOGIES)
|
||||
|
||||
for technology in os_specific_techologies:
|
||||
# TODO move the functions definisions to function_calls.py
|
||||
for technology in os_specific_technologies:
|
||||
# TODO move the functions definitions to function_calls.py
|
||||
cli_response, llm_response = self.convo_os_specific_tech.send_message('development/env_setup/install_next_technology.prompt',
|
||||
{ 'technology': technology}, {
|
||||
'definitions': [{
|
||||
@@ -333,7 +339,7 @@ class Developer(Agent):
|
||||
},
|
||||
'timeout': {
|
||||
'type': 'number',
|
||||
'description': f'Timeout in seconds for the approcimate time this command takes to finish.',
|
||||
'description': 'Timeout in seconds for the approcimate time this command takes to finish.',
|
||||
}
|
||||
},
|
||||
'required': ['command', 'timeout'],
|
||||
@@ -352,10 +358,10 @@ class Developer(Agent):
|
||||
for cmd in installation_commands:
|
||||
run_command_until_success(cmd['command'], cmd['timeout'], self.convo_os_specific_tech)
|
||||
|
||||
logger.info('The entire tech stack neede is installed and ready to be used.')
|
||||
logger.info('The entire tech stack needed is installed and ready to be used.')
|
||||
|
||||
save_progress(self.project.args['app_id'], self.project.current_step, {
|
||||
"os_specific_techologies": os_specific_techologies, "newly_installed_technologies": [], "app_data": generate_app_data(self.project.args)
|
||||
"os_specific_technologies": os_specific_technologies, "newly_installed_technologies": [], "app_data": generate_app_data(self.project.args)
|
||||
})
|
||||
|
||||
# ENVIRONMENT SETUP END
|
||||
@@ -395,11 +401,11 @@ class Developer(Agent):
|
||||
'step_type': type,
|
||||
'directory_tree': directory_tree,
|
||||
'step_index': step_index
|
||||
}, EXECUTE_COMMANDS);
|
||||
}, EXECUTE_COMMANDS)
|
||||
if type == 'COMMAND':
|
||||
for cmd in step_details:
|
||||
run_command_until_success(cmd['command'], cmd['timeout'], convo)
|
||||
elif type == 'CODE_CHANGE':
|
||||
code_changes_details = get_step_code_changes()
|
||||
# elif type == 'CODE_CHANGE':
|
||||
# code_changes_details = get_step_code_changes()
|
||||
# TODO: give to code monkey for implementation
|
||||
pass
|
||||
|
||||
@@ -4,12 +4,16 @@ from helpers.AgentConvo import AgentConvo
|
||||
from helpers.Agent import Agent
|
||||
from logger.logger import logger
|
||||
from database.database import save_progress, save_app, get_progress_steps
|
||||
from utils.utils import execute_step, generate_app_data, step_already_finished, clean_filename
|
||||
from utils.utils import should_execute_step, generate_app_data, step_already_finished, clean_filename
|
||||
from utils.files import setup_workspace
|
||||
from prompts.prompts import ask_for_app_type, ask_for_main_app_definition, get_additional_info_from_openai, \
|
||||
generate_messages_from_description, ask_user
|
||||
from const.llm import END_RESPONSE
|
||||
|
||||
PROJECT_DESCRIPTION_STEP = 'project_description'
|
||||
USER_STORIES_STEP = 'user_stories'
|
||||
USER_TASKS_STEP = 'user_tasks'
|
||||
|
||||
|
||||
class ProductOwner(Agent):
|
||||
def __init__(self, project):
|
||||
@@ -17,23 +21,24 @@ class ProductOwner(Agent):
|
||||
|
||||
def get_project_description(self):
|
||||
self.project.app = save_app(self.project.args)
|
||||
self.project.current_step = 'project_description'
|
||||
convo_project_description = AgentConvo(self)
|
||||
self.project.current_step = PROJECT_DESCRIPTION_STEP
|
||||
|
||||
# If this app_id already did this step, just get all data from DB and don't ask user again
|
||||
step = get_progress_steps(self.project.args['app_id'], self.project.current_step)
|
||||
if step and not execute_step(self.project.args['step'], self.project.current_step):
|
||||
step = get_progress_steps(self.project.args['app_id'], PROJECT_DESCRIPTION_STEP)
|
||||
if step and not should_execute_step(self.project.args['step'], PROJECT_DESCRIPTION_STEP):
|
||||
step_already_finished(self.project.args, step)
|
||||
self.project.root_path = setup_workspace(self.project.args['name'])
|
||||
self.project.root_path = setup_workspace(self.project.args)
|
||||
self.project.project_description = step['summary']
|
||||
self.project.project_description_messages = step['messages']
|
||||
return
|
||||
|
||||
# PROJECT DESCRIPTION
|
||||
self.project.args['app_type'] = ask_for_app_type()
|
||||
self.project.args['name'] = clean_filename(ask_user(self.project, 'What is the project name?'))
|
||||
if 'app_type' not in self.project.args:
|
||||
self.project.args['app_type'] = ask_for_app_type()
|
||||
if 'name' not in self.project.args:
|
||||
self.project.args['name'] = clean_filename(ask_user(self.project, 'What is the project name?'))
|
||||
|
||||
self.project.root_path = setup_workspace(self.project.args['name'])
|
||||
self.project.root_path = setup_workspace(self.project.args)
|
||||
|
||||
self.project.app = save_app(self.project.args)
|
||||
|
||||
@@ -44,8 +49,11 @@ class ProductOwner(Agent):
|
||||
generate_messages_from_description(main_prompt, self.project.args['app_type'], self.project.args['name']))
|
||||
|
||||
print(green(bold('Project Summary:\n')))
|
||||
convo_project_description = AgentConvo(self)
|
||||
high_level_summary = convo_project_description.send_message('utils/summary.prompt',
|
||||
{'conversation': '\n'.join([f"{msg['role']}: {msg['content']}" for msg in high_level_messages])})
|
||||
{'conversation': '\n'.join(
|
||||
[f"{msg['role']}: {msg['content']}" for msg in
|
||||
high_level_messages])})
|
||||
|
||||
save_progress(self.project.args['app_id'], self.project.current_step, {
|
||||
"prompt": main_prompt,
|
||||
@@ -59,14 +67,13 @@ class ProductOwner(Agent):
|
||||
return
|
||||
# PROJECT DESCRIPTION END
|
||||
|
||||
|
||||
def get_user_stories(self):
|
||||
self.project.current_step = 'user_stories'
|
||||
self.project.current_step = USER_STORIES_STEP
|
||||
self.convo_user_stories = AgentConvo(self)
|
||||
|
||||
# If this app_id already did this step, just get all data from DB and don't ask user again
|
||||
step = get_progress_steps(self.project.args['app_id'], self.project.current_step)
|
||||
if step and not execute_step(self.project.args['step'], self.project.current_step):
|
||||
step = get_progress_steps(self.project.args['app_id'], USER_STORIES_STEP)
|
||||
if step and not should_execute_step(self.project.args['step'], USER_STORIES_STEP):
|
||||
step_already_finished(self.project.args, step)
|
||||
self.convo_user_stories.messages = step['messages']
|
||||
return step['user_stories']
|
||||
@@ -96,12 +103,12 @@ class ProductOwner(Agent):
|
||||
# USER STORIES END
|
||||
|
||||
def get_user_tasks(self):
|
||||
self.project.current_step = 'user_tasks'
|
||||
self.project.current_step = USER_TASKS_STEP
|
||||
self.convo_user_stories.high_level_step = self.project.current_step
|
||||
|
||||
# If this app_id already did this step, just get all data from DB and don't ask user again
|
||||
step = get_progress_steps(self.project.args['app_id'], self.project.current_step)
|
||||
if step and not execute_step(self.project.args['step'], self.project.current_step):
|
||||
step = get_progress_steps(self.project.args['app_id'], USER_TASKS_STEP)
|
||||
if step and not should_execute_step(self.project.args['step'], USER_TASKS_STEP):
|
||||
step_already_finished(self.project.args, step)
|
||||
return step['user_tasks']
|
||||
|
||||
@@ -111,7 +118,7 @@ class ProductOwner(Agent):
|
||||
logger.info(msg)
|
||||
|
||||
self.project.user_tasks = self.convo_user_stories.continuous_conversation('user_stories/user_tasks.prompt',
|
||||
{ 'END_RESPONSE': END_RESPONSE })
|
||||
{'END_RESPONSE': END_RESPONSE})
|
||||
|
||||
logger.info(f"Final user tasks: {self.project.user_tasks}")
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@ from const.function_calls import DEV_STEPS
|
||||
from helpers.cli import build_directory_tree
|
||||
from helpers.AgentConvo import AgentConvo
|
||||
|
||||
from utils.utils import execute_step, array_of_objects_to_string, generate_app_data
|
||||
from utils.utils import should_execute_step, array_of_objects_to_string, generate_app_data
|
||||
from database.database import save_progress, get_progress_steps
|
||||
from logger.logger import logger
|
||||
from const.function_calls import FILTER_OS_TECHNOLOGIES, DEVELOPMENT_PLAN, EXECUTE_COMMANDS
|
||||
@@ -14,17 +14,20 @@ from const.code_execution import MAX_COMMAND_DEBUG_TRIES
|
||||
from utils.utils import get_os_info
|
||||
from helpers.cli import execute_command
|
||||
|
||||
DEVELOPMENT_PLANNING_STEP = 'development_planning'
|
||||
|
||||
|
||||
class TechLead(Agent):
|
||||
def __init__(self, project):
|
||||
super().__init__('tech_lead', project)
|
||||
|
||||
def create_development_plan(self):
|
||||
self.project.current_step = 'development_planning'
|
||||
self.project.current_step = DEVELOPMENT_PLANNING_STEP
|
||||
self.convo_development_plan = AgentConvo(self)
|
||||
|
||||
# If this app_id already did this step, just get all data from DB and don't ask user again
|
||||
step = get_progress_steps(self.project.args['app_id'], self.project.current_step)
|
||||
if step and not execute_step(self.project.args['step'], self.project.current_step):
|
||||
step = get_progress_steps(self.project.args['app_id'], DEVELOPMENT_PLANNING_STEP)
|
||||
if step and not should_execute_step(self.project.args['step'], DEVELOPMENT_PLANNING_STEP):
|
||||
step_already_finished(self.project.args, step)
|
||||
return step['development_plan']
|
||||
|
||||
@@ -36,6 +39,7 @@ class TechLead(Agent):
|
||||
self.development_plan = self.convo_development_plan.send_message('development/plan.prompt',
|
||||
{
|
||||
"name": self.project.args['name'],
|
||||
"app_type": self.project.args['app_type'],
|
||||
"app_summary": self.project.project_description,
|
||||
"clarification": [],
|
||||
"user_stories": self.project.user_stories,
|
||||
|
||||
120
pilot/helpers/agents/test_CodeMonkey.py
Normal file
120
pilot/helpers/agents/test_CodeMonkey.py
Normal file
@@ -0,0 +1,120 @@
|
||||
import re
|
||||
import os
|
||||
from unittest.mock import patch, Mock, MagicMock
|
||||
from dotenv import load_dotenv
|
||||
load_dotenv()
|
||||
|
||||
from .CodeMonkey import CodeMonkey
|
||||
from .Developer import Developer
|
||||
from database.models.files import File
|
||||
from helpers.Project import Project, update_file, clear_directory
|
||||
from helpers.AgentConvo import AgentConvo
|
||||
|
||||
SEND_TO_LLM = False
|
||||
WRITE_TO_FILE = False
|
||||
|
||||
|
||||
def mock_terminal_size():
|
||||
mock_size = Mock()
|
||||
mock_size.columns = 80 # or whatever width you want
|
||||
return mock_size
|
||||
|
||||
|
||||
class TestCodeMonkey:
|
||||
def setup_method(self):
|
||||
name = 'TestDeveloper'
|
||||
self.project = Project({
|
||||
'app_id': 'test-developer',
|
||||
'name': name,
|
||||
'app_type': ''
|
||||
},
|
||||
name=name,
|
||||
architecture=[],
|
||||
user_stories=[],
|
||||
current_step='coding',
|
||||
)
|
||||
|
||||
self.project.root_path = os.path.abspath(os.path.join(os.path.dirname(os.path.abspath(__file__)),
|
||||
'../../../workspace/TestDeveloper'))
|
||||
self.project.technologies = []
|
||||
self.project.app = None
|
||||
self.developer = Developer(self.project)
|
||||
self.codeMonkey = CodeMonkey(self.project, developer=self.developer)
|
||||
|
||||
@patch('helpers.AgentConvo.get_development_step_from_hash_id', return_value=None)
|
||||
@patch('helpers.AgentConvo.save_development_step', return_value=None)
|
||||
@patch('os.get_terminal_size', mock_terminal_size)
|
||||
@patch.object(File, 'insert')
|
||||
def test_implement_code_changes(self, mock_get_dev, mock_save_dev, mock_file_insert):
|
||||
# Given
|
||||
code_changes_description = "Write the word 'Washington' to a .txt file"
|
||||
|
||||
if SEND_TO_LLM:
|
||||
convo = AgentConvo(self.codeMonkey)
|
||||
else:
|
||||
convo = MagicMock()
|
||||
mock_responses = [
|
||||
[],
|
||||
[{
|
||||
'content': 'Washington',
|
||||
'description': "A new .txt file with the word 'Washington' in it.",
|
||||
'name': 'washington.txt',
|
||||
'path': 'washington.txt'
|
||||
}]
|
||||
]
|
||||
convo.send_message.side_effect = mock_responses
|
||||
|
||||
if WRITE_TO_FILE:
|
||||
self.codeMonkey.implement_code_changes(convo, code_changes_description)
|
||||
else:
|
||||
# don't write the file, just
|
||||
with patch.object(Project, 'save_file') as mock_save_file:
|
||||
# When
|
||||
self.codeMonkey.implement_code_changes(convo, code_changes_description)
|
||||
|
||||
# Then
|
||||
mock_save_file.assert_called_once()
|
||||
called_data = mock_save_file.call_args[0][0]
|
||||
assert re.match(r'\w+\.txt$', called_data['name'])
|
||||
assert (called_data['path'] == '/' or called_data['path'] == called_data['name'])
|
||||
assert called_data['content'] == 'Washington'
|
||||
|
||||
@patch('helpers.AgentConvo.get_development_step_from_hash_id', return_value=None)
|
||||
@patch('helpers.AgentConvo.save_development_step', return_value=None)
|
||||
@patch('os.get_terminal_size', mock_terminal_size)
|
||||
@patch.object(File, 'insert')
|
||||
def test_implement_code_changes_with_read(self, mock_get_dev, mock_save_dev, mock_file_insert):
|
||||
# Given
|
||||
code_changes_description = "Read the file called file_to_read.txt and write its content to a file called output.txt"
|
||||
workspace = self.project.root_path
|
||||
update_file(os.path.join(workspace, 'file_to_read.txt'), 'Hello World!\n')
|
||||
|
||||
if SEND_TO_LLM:
|
||||
convo = AgentConvo(self.codeMonkey)
|
||||
else:
|
||||
convo = MagicMock()
|
||||
mock_responses = [
|
||||
['file_to_read.txt', 'output.txt'],
|
||||
[{
|
||||
'content': 'Hello World!\n',
|
||||
'description': 'This file is the output file. The content of file_to_read.txt is copied into this file.',
|
||||
'name': 'output.txt',
|
||||
'path': 'output.txt'
|
||||
}]
|
||||
]
|
||||
convo.send_message.side_effect = mock_responses
|
||||
|
||||
if WRITE_TO_FILE:
|
||||
self.codeMonkey.implement_code_changes(convo, code_changes_description)
|
||||
else:
|
||||
with patch.object(Project, 'save_file') as mock_save_file:
|
||||
# When
|
||||
self.codeMonkey.implement_code_changes(convo, code_changes_description)
|
||||
|
||||
# Then
|
||||
clear_directory(workspace)
|
||||
mock_save_file.assert_called_once()
|
||||
called_data = mock_save_file.call_args[0][0]
|
||||
assert called_data['name'] == 'output.txt'
|
||||
assert (called_data['path'] == '/' or called_data['path'] == called_data['name'])
|
||||
assert called_data['content'] == 'Hello World!\n'
|
||||
0
pilot/logger/__init__.py
Normal file
0
pilot/logger/__init__.py
Normal file
@@ -4,21 +4,20 @@ import builtins
|
||||
import json
|
||||
|
||||
import sys
|
||||
|
||||
import traceback
|
||||
from dotenv import load_dotenv
|
||||
load_dotenv()
|
||||
|
||||
from termcolor import colored
|
||||
from helpers.ipc import IPCClient
|
||||
from const.ipc import MESSAGE_TYPE
|
||||
from utils.utils import json_serial
|
||||
|
||||
from helpers.Project import Project
|
||||
|
||||
from utils.arguments import get_arguments
|
||||
from utils.exit import exit_gpt_pilot
|
||||
from logger.logger import logger
|
||||
from database.database import database_exists, create_database, tables_exist, create_tables, get_created_apps_with_steps
|
||||
|
||||
|
||||
def init():
|
||||
# Check if the "euclid" database exists, if not, create it
|
||||
if not database_exists():
|
||||
@@ -86,6 +85,9 @@ if __name__ == "__main__":
|
||||
except KeyboardInterrupt:
|
||||
exit_gpt_pilot()
|
||||
except Exception as e:
|
||||
print(colored('---------- GPT PILOT EXITING WITH ERROR ----------', 'red'))
|
||||
traceback.print_exc()
|
||||
print(colored('--------------------------------------------------', 'red'))
|
||||
exit_gpt_pilot()
|
||||
finally:
|
||||
sys.exit(0)
|
||||
|
||||
@@ -7,7 +7,7 @@ You wanted me to check this - `{{ issue_description }}` but there was a problem{
|
||||
|
||||
`run_command` function will run a command on the machine and will return the CLI output to you so you can see what to do next.
|
||||
|
||||
`implement_code_changes` function will change the code where you just need to thoroughly describe what needs to be implmemented, I will implement the requested changes and let you know.
|
||||
`implement_code_changes` function will change the code where you just need to thoroughly describe what needs to be implemented, I will implement the requested changes and let you know.
|
||||
|
||||
Return a list of steps that are needed to debug this issue. By the time we execute the last step, the issue should be fixed completely. Also, make sure that at least the last step has `check_if_fixed` set to TRUE.
|
||||
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
You are working in a software development agency and a project manager and software architect approach you telling you that you're assigned to work on a new project. You are working on a web app called "{{ name }}" and your first job is to set up the environment on a computer.
|
||||
You are working in a software development agency and a project manager and software architect approach you telling you that you're assigned to work on a new project. You are working on a {{ app_type }} called "{{ name }}" and your first job is to set up the environment on a computer.
|
||||
|
||||
Here are the technologies that you need to use for this project:
|
||||
```
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
You are working on a web app called "{{ name }}" and you need to write code for the entire application.
|
||||
You are working on a {{ app_type }} called "{{ name }}" and you need to write code for the entire application.
|
||||
|
||||
Here is a high level description of "{{ name }}":
|
||||
```
|
||||
|
||||
@@ -1 +1 @@
|
||||
Ok, now, take your previous message and convert it to actionable items. An item might be a code change or a command run. When you need to change code, make sure that you put the entire content of the file in the value of `content` key even though you will likely copy and paste the most of the previous messsage.
|
||||
Ok, now, take your previous message and convert it to actionable items. An item might be a code change or a command run. When you need to change code, make sure that you put the entire content of the file in the value of `content` key even though you will likely copy and paste the most of the previous message.
|
||||
@@ -1,4 +1,4 @@
|
||||
You are working in a software development agency and a project manager and software architect approach you telling you that you're assigned to work on a new project. You are working on a web app called "{{ name }}" and you need to create a detailed development plan so that developers can start developing the app.
|
||||
You are working in a software development agency and a project manager and software architect approach you telling you that you're assigned to work on a new project. You are working on a {{ app_type }} called "{{ name }}" and you need to create a detailed development plan so that developers can start developing the app.
|
||||
|
||||
Here is a high level description of "{{ name }}":
|
||||
```
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
You are working on a web app called "{{ name }}" and you need to write code for the entire application based on the tasks that the tech lead gives you. So that you understand better what you're working on, you're given other specs for "{{ name }}" as well.
|
||||
You are working on a {{ app_type }} called "{{ name }}" and you need to write code for the entire application based on the tasks that the tech lead gives you. So that you understand better what you're working on, you're given other specs for "{{ name }}" as well.
|
||||
|
||||
Here is a high level description of "{{ name }}":
|
||||
```
|
||||
|
||||
@@ -12,7 +12,7 @@ from logger.logger import logger
|
||||
|
||||
|
||||
def ask_for_app_type():
|
||||
return 'app'
|
||||
return 'Web App'
|
||||
answer = styled_select(
|
||||
"What type of app do you want to build?",
|
||||
choices=common.APP_TYPES
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
You are an experienced software architect. Your expertise is in creating an architecture for an MVP (minimum viable products) for web apps that can be developed as fast as possible by using as many ready-made technologies as possible. The technologies that you prefer using when other technologies are not explicitly specified are:
|
||||
You are an experienced software architect. Your expertise is in creating an architecture for an MVP (minimum viable products) for {{ app_type }}s that can be developed as fast as possible by using as many ready-made technologies as possible. The technologies that you prefer using when other technologies are not explicitly specified are:
|
||||
**Scripts**: you prefer using Node.js for writing scripts that are meant to be ran just with the CLI.
|
||||
|
||||
**Backend**: you prefer using Node.js with Mongo database if not explicitely specified otherwise. When you're using Mongo, you always use Mongoose and when you're using Postgresql, you always use PeeWee as an ORM.
|
||||
|
||||
@@ -1,7 +1,11 @@
|
||||
import hashlib
|
||||
import os
|
||||
import re
|
||||
import sys
|
||||
import uuid
|
||||
|
||||
from database.database import get_app
|
||||
from getpass import getuser
|
||||
from termcolor import colored
|
||||
from database.database import get_app, get_app_by_user_workspace
|
||||
|
||||
|
||||
def get_arguments():
|
||||
@@ -20,26 +24,41 @@ def get_arguments():
|
||||
else:
|
||||
arguments[arg] = True
|
||||
|
||||
if 'user_id' not in arguments:
|
||||
arguments['user_id'] = username_to_uuid(getuser())
|
||||
|
||||
app = None
|
||||
if 'workspace' in arguments:
|
||||
app = get_app_by_user_workspace(arguments['user_id'], arguments['workspace'])
|
||||
if app is not None:
|
||||
arguments['app_id'] = app.id
|
||||
else:
|
||||
arguments['workspace'] = None
|
||||
|
||||
if 'app_id' in arguments:
|
||||
try:
|
||||
app = get_app(arguments['app_id'])
|
||||
arguments['user_id'] = str(app.user.id)
|
||||
if app is None:
|
||||
app = get_app(arguments['app_id'])
|
||||
|
||||
arguments['app_type'] = app.app_type
|
||||
arguments['name'] = app.name
|
||||
# Add any other fields from the App model you wish to include
|
||||
|
||||
print(colored('\n------------------ LOADING PROJECT ----------------------', 'green', attrs=['bold']))
|
||||
print(colored(f'{app.name} (app_id={arguments["app_id"]})', 'green', attrs=['bold']))
|
||||
print(colored('--------------------------------------------------------------\n', 'green', attrs=['bold']))
|
||||
except ValueError as e:
|
||||
print(e)
|
||||
# Handle the error as needed, possibly exiting the script
|
||||
else:
|
||||
arguments['app_id'] = str(uuid.uuid4())
|
||||
|
||||
if 'user_id' not in arguments:
|
||||
arguments['user_id'] = str(uuid.uuid4())
|
||||
print(colored('\n------------------ STARTING NEW PROJECT ----------------------', 'green', attrs=['bold']))
|
||||
print("If you wish to continue with this project in future run:")
|
||||
print(colored(f'python {sys.argv[0]} app_id={arguments["app_id"]}', 'green', attrs=['bold']))
|
||||
print(colored('--------------------------------------------------------------\n', 'green', attrs=['bold']))
|
||||
|
||||
if 'email' not in arguments:
|
||||
# todo change email so its not uuid4 but make sure to fix storing of development steps where
|
||||
# 1 user can have multiple apps. In that case each app should have its own development steps
|
||||
arguments['email'] = str(uuid.uuid4())
|
||||
arguments['email'] = get_email()
|
||||
|
||||
if 'password' not in arguments:
|
||||
arguments['password'] = 'password'
|
||||
@@ -48,3 +67,30 @@ def get_arguments():
|
||||
arguments['step'] = None
|
||||
|
||||
return arguments
|
||||
|
||||
|
||||
def get_email():
|
||||
# Attempt to get email from .gitconfig
|
||||
gitconfig_path = os.path.expanduser('~/.gitconfig')
|
||||
|
||||
if os.path.exists(gitconfig_path):
|
||||
with open(gitconfig_path, 'r') as file:
|
||||
content = file.read()
|
||||
|
||||
# Use regex to search for email address
|
||||
email_match = re.search(r'email\s*=\s*([\w\.-]+@[\w\.-]+)', content)
|
||||
|
||||
if email_match:
|
||||
return email_match.group(1)
|
||||
|
||||
# If not found, return a UUID
|
||||
# todo change email so its not uuid4 but make sure to fix storing of development steps where
|
||||
# 1 user can have multiple apps. In that case each app should have its own development steps
|
||||
return str(uuid.uuid4())
|
||||
|
||||
|
||||
# TODO can we make BaseModel.id a CharField with default=uuid4?
|
||||
def username_to_uuid(username):
|
||||
sha1 = hashlib.sha1(username.encode()).hexdigest()
|
||||
uuid_str = "{}-{}-{}-{}-{}".format(sha1[:8], sha1[8:12], sha1[12:16], sha1[16:20], sha1[20:32])
|
||||
return str(uuid.UUID(uuid_str))
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
from database.database import save_user_app
|
||||
|
||||
def get_parent_folder(folder_name):
|
||||
current_path = Path(os.path.abspath(__file__)) # get the path of the current script
|
||||
@@ -11,10 +11,18 @@ def get_parent_folder(folder_name):
|
||||
return current_path.parent
|
||||
|
||||
|
||||
def setup_workspace(project_name):
|
||||
def setup_workspace(args):
|
||||
if args['workspace'] is not None:
|
||||
try:
|
||||
save_user_app(args['user_id'], args['app_id'], args['workspace'])
|
||||
except Exception as e:
|
||||
print(str(e))
|
||||
|
||||
return args['workspace']
|
||||
|
||||
root = get_parent_folder('pilot')
|
||||
create_directory(root, 'workspace')
|
||||
project_path = create_directory(os.path.join(root, 'workspace'), project_name)
|
||||
project_path = create_directory(os.path.join(root, 'workspace'), args['name'])
|
||||
create_directory(project_path, 'tests')
|
||||
return project_path
|
||||
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
import re
|
||||
import requests
|
||||
import os
|
||||
import sys
|
||||
import time
|
||||
import json
|
||||
import tiktoken
|
||||
import questionary
|
||||
@@ -83,7 +85,23 @@ def num_tokens_from_functions(functions, model=model):
|
||||
|
||||
|
||||
def create_gpt_chat_completion(messages: List[dict], req_type, min_tokens=MIN_TOKENS_FOR_GPT_RESPONSE,
|
||||
function_calls=None):
|
||||
function_calls=None):
|
||||
"""
|
||||
Called from:
|
||||
- AgentConvo.send_message() - these calls often have `function_calls`, usually from `pilot/const/function_calls.py`
|
||||
- convo.continuous_conversation()
|
||||
- prompts.get_additional_info_from_openai()
|
||||
- prompts.get_additional_info_from_user() after the user responds to each
|
||||
"Please check this message and say what needs to be changed... {message}"
|
||||
:param messages: [{ "role": "system"|"assistant"|"user", "content": string }, ... ]
|
||||
:param req_type: 'project_description' etc. See common.STEPS
|
||||
:param min_tokens: defaults to 600
|
||||
:param function_calls: (optional) {'definitions': [{ 'name': str }, ...]}
|
||||
see `IMPLEMENT_CHANGES` etc. in `pilot/const/function_calls.py`
|
||||
:return: {'text': new_code}
|
||||
or if `function_calls` param provided
|
||||
{'function_calls': {'name': str, arguments: {...}}}
|
||||
"""
|
||||
|
||||
tokens_in_messages = round(get_tokens_in_messages(messages) * 1.2) # add 20% to account for not 100% accuracy
|
||||
if function_calls is not None:
|
||||
@@ -93,7 +111,7 @@ def create_gpt_chat_completion(messages: List[dict], req_type, min_tokens=MIN_TO
|
||||
raise TokenLimitError(tokens_in_messages + min_tokens, MAX_GPT_MODEL_TOKENS)
|
||||
|
||||
gpt_data = {
|
||||
'model': os.getenv('OPENAI_MODEL', 'gpt-4'),
|
||||
'model': os.getenv('MODEL_NAME', 'gpt-4'),
|
||||
'n': 1,
|
||||
'temperature': 1,
|
||||
'top_p': 1,
|
||||
@@ -103,7 +121,15 @@ def create_gpt_chat_completion(messages: List[dict], req_type, min_tokens=MIN_TO
|
||||
'stream': True
|
||||
}
|
||||
|
||||
# delete some keys if using "OpenRouter" API
|
||||
if os.getenv('ENDPOINT') == "OPENROUTER":
|
||||
keys_to_delete = ['n', 'max_tokens', 'temperature', 'top_p', 'presence_penalty', 'frequency_penalty']
|
||||
for key in keys_to_delete:
|
||||
if key in gpt_data:
|
||||
del gpt_data[key]
|
||||
|
||||
if function_calls is not None:
|
||||
# Advise the LLM of the JSON response schema we are expecting
|
||||
gpt_data['functions'] = function_calls['definitions']
|
||||
if len(function_calls['definitions']) > 1:
|
||||
gpt_data['function_call'] = 'auto'
|
||||
@@ -149,6 +175,13 @@ def retry_on_exception(func):
|
||||
# If the specific error "context_length_exceeded" is present, simply return without retry
|
||||
if "context_length_exceeded" in err_str:
|
||||
raise TokenLimitError(tokens_in_messages + min_tokens, MAX_GPT_MODEL_TOKENS)
|
||||
if "rate_limit_exceeded" in err_str:
|
||||
# Extracting the duration from the error string
|
||||
match = re.search(r"Please try again in (\d+)ms.", err_str)
|
||||
if match:
|
||||
wait_duration = int(match.group(1)) / 1000
|
||||
time.sleep(wait_duration)
|
||||
continue
|
||||
|
||||
print(red(f'There was a problem with request to openai API:'))
|
||||
print(err_str)
|
||||
@@ -168,6 +201,13 @@ def retry_on_exception(func):
|
||||
|
||||
@retry_on_exception
|
||||
def stream_gpt_completion(data, req_type):
|
||||
"""
|
||||
Called from create_gpt_chat_completion()
|
||||
:param data:
|
||||
:param req_type: 'project_description' etc. See common.STEPS
|
||||
:return: {'text': str} or {'function_calls': {'name': str, arguments: '{...}'}}
|
||||
"""
|
||||
|
||||
# TODO add type dynamically - this isn't working when connected to the external process
|
||||
terminal_width = 50#os.get_terminal_size().columns
|
||||
lines_printed = 2
|
||||
@@ -192,10 +232,14 @@ def stream_gpt_completion(data, req_type):
|
||||
# If yes, get the AZURE_ENDPOINT from .ENV file
|
||||
endpoint_url = os.getenv('AZURE_ENDPOINT') + '/openai/deployments/' + model + '/chat/completions?api-version=2023-05-15'
|
||||
headers = {'Content-Type': 'application/json', 'api-key': os.getenv('AZURE_API_KEY')}
|
||||
elif endpoint == 'OPENROUTER':
|
||||
# If so, send the request to the OpenRouter API endpoint
|
||||
headers = {'Content-Type': 'application/json', 'Authorization': 'Bearer ' + os.getenv("OPENROUTER_API_KEY"), 'HTTP-Referer': 'http://localhost:3000', 'X-Title': 'GPT Pilot (LOCAL)'}
|
||||
endpoint_url = os.getenv("OPENROUTER_ENDPOINT", 'https://openrouter.ai/api/v1/chat/completions')
|
||||
else:
|
||||
# If not, send the request to the OpenAI endpoint
|
||||
headers = {'Content-Type': 'application/json', 'Authorization': 'Bearer ' + os.getenv("OPENAI_API_KEY")}
|
||||
endpoint_url = 'https://api.openai.com/v1/chat/completions'
|
||||
endpoint_url = os.getenv("OPENAI_ENDPOINT", 'https://api.openai.com/v1/chat/completions')
|
||||
|
||||
response = requests.post(
|
||||
endpoint_url,
|
||||
@@ -229,13 +273,17 @@ def stream_gpt_completion(data, req_type):
|
||||
|
||||
try:
|
||||
json_line = json.loads(line)
|
||||
|
||||
if len(json_line['choices']) == 0:
|
||||
continue
|
||||
|
||||
if 'error' in json_line:
|
||||
logger.error(f'Error in LLM response: {json_line}')
|
||||
raise ValueError(f'Error in LLM response: {json_line["error"]["message"]}')
|
||||
|
||||
if json_line['choices'][0]['finish_reason'] == 'function_call':
|
||||
function_calls['arguments'] = load_data_to_json(function_calls['arguments'])
|
||||
return return_result({'function_calls': function_calls}, lines_printed);
|
||||
return return_result({'function_calls': function_calls}, lines_printed)
|
||||
|
||||
json_line = json_line['choices'][0]['delta']
|
||||
|
||||
@@ -243,6 +291,7 @@ def stream_gpt_completion(data, req_type):
|
||||
logger.error(f'Unable to decode line: {line}')
|
||||
continue # skip to the next line
|
||||
|
||||
# handle the streaming response
|
||||
if 'function_call' in json_line:
|
||||
if 'name' in json_line['function_call']:
|
||||
function_calls['name'] = json_line['function_call']['name']
|
||||
|
||||
@@ -51,4 +51,4 @@ def get_user_feedback():
|
||||
config = {
|
||||
'style': custom_style,
|
||||
}
|
||||
return questionary.text("Thank you for trying GPT-Pilot. Please give us your feedback or just press ENTER to exit: ", **config).unsafe_ask()
|
||||
return questionary.text("How did GPT Pilot do? Were you able to create any app that works? Please write any feedback you have or just press ENTER to exit: ", **config).unsafe_ask()
|
||||
|
||||
40
pilot/utils/test_arguments.py
Normal file
40
pilot/utils/test_arguments.py
Normal file
@@ -0,0 +1,40 @@
|
||||
import pytest
|
||||
from unittest.mock import patch, mock_open
|
||||
import uuid
|
||||
from .arguments import get_email, username_to_uuid
|
||||
|
||||
|
||||
def test_email_found_in_gitconfig():
|
||||
mock_file_content = """
|
||||
[user]
|
||||
name = test_user
|
||||
email = test@example.com
|
||||
"""
|
||||
with patch('os.path.exists', return_value=True):
|
||||
with patch('builtins.open', mock_open(read_data=mock_file_content)):
|
||||
assert get_email() == "test@example.com"
|
||||
|
||||
|
||||
def test_email_not_found_in_gitconfig():
|
||||
mock_file_content = """
|
||||
[user]
|
||||
name = test_user
|
||||
"""
|
||||
mock_uuid = "12345678-1234-5678-1234-567812345678"
|
||||
|
||||
with patch('os.path.exists', return_value=True):
|
||||
with patch('builtins.open', mock_open(read_data=mock_file_content)):
|
||||
with patch.object(uuid, "uuid4", return_value=mock_uuid):
|
||||
assert get_email() == mock_uuid
|
||||
|
||||
|
||||
def test_gitconfig_not_present():
|
||||
mock_uuid = "12345678-1234-5678-1234-567812345678"
|
||||
|
||||
with patch('os.path.exists', return_value=False):
|
||||
with patch.object(uuid, "uuid4", return_value=mock_uuid):
|
||||
assert get_email() == mock_uuid
|
||||
|
||||
|
||||
def test_username_to_uuid():
|
||||
assert username_to_uuid("test_user") == "31676025-316f-b555-e0bf-a12f0bcfd0ea"
|
||||
26
pilot/utils/test_files.py
Normal file
26
pilot/utils/test_files.py
Normal file
@@ -0,0 +1,26 @@
|
||||
import pytest
|
||||
from .files import setup_workspace
|
||||
|
||||
|
||||
def test_setup_workspace_with_existing_workspace():
|
||||
args = {'workspace': 'some_directory', 'name': 'sample'}
|
||||
result = setup_workspace(args)
|
||||
assert result == 'some_directory'
|
||||
|
||||
|
||||
def mocked_create_directory(path, exist_ok=True):
|
||||
return
|
||||
|
||||
|
||||
def mocked_abspath(file):
|
||||
return "/root_path/pilot/helpers"
|
||||
|
||||
|
||||
def test_setup_workspace_without_existing_workspace(monkeypatch):
|
||||
args = {'workspace': None, 'name': 'project_name'}
|
||||
|
||||
monkeypatch.setattr('os.path.abspath', mocked_abspath)
|
||||
monkeypatch.setattr('os.makedirs', mocked_create_directory)
|
||||
|
||||
result = setup_workspace(args)
|
||||
assert result.replace('\\', '/') == "/root_path/workspace/project_name"
|
||||
19
pilot/utils/test_utils.py
Normal file
19
pilot/utils/test_utils.py
Normal file
@@ -0,0 +1,19 @@
|
||||
from .utils import should_execute_step
|
||||
|
||||
|
||||
class TestShouldExecuteStep:
|
||||
def test_no_step_arg(self):
|
||||
assert should_execute_step(None, 'project_description') is True
|
||||
assert should_execute_step(None, 'architecture') is True
|
||||
assert should_execute_step(None, 'coding') is True
|
||||
|
||||
def test_skip_step(self):
|
||||
assert should_execute_step('architecture', 'project_description') is False
|
||||
assert should_execute_step('architecture', 'architecture') is True
|
||||
assert should_execute_step('architecture', 'coding') is True
|
||||
|
||||
def test_unknown_step(self):
|
||||
assert should_execute_step('architecture', 'unknown') is False
|
||||
assert should_execute_step('unknown', 'project_description') is False
|
||||
assert should_execute_step('unknown', None) is False
|
||||
assert should_execute_step(None, None) is False
|
||||
@@ -110,11 +110,16 @@ def get_os_info():
|
||||
return array_of_objects_to_string(os_info)
|
||||
|
||||
|
||||
def execute_step(matching_step, current_step):
|
||||
matching_step_index = STEPS.index(matching_step) if matching_step in STEPS else None
|
||||
def should_execute_step(arg_step, current_step):
|
||||
"""
|
||||
:param arg_step: `project.args['step']`, may be None
|
||||
:param current_step: The step that would be executed next by the calling method.
|
||||
:return: True if `current_step` should be executed.
|
||||
"""
|
||||
arg_step_index = 0 if arg_step is None else STEPS.index(arg_step) if arg_step in STEPS else None
|
||||
current_step_index = STEPS.index(current_step) if current_step in STEPS else None
|
||||
|
||||
return matching_step_index is not None and current_step_index is not None and current_step_index >= matching_step_index
|
||||
return arg_step_index is not None and current_step_index is not None and current_step_index >= arg_step_index
|
||||
|
||||
|
||||
def step_already_finished(args, step):
|
||||
|
||||
Reference in New Issue
Block a user