mirror of
https://github.com/OMGeeky/gpt-pilot.git
synced 2026-02-23 15:49:50 +01:00
Merge branch 'main' into main
This commit is contained in:
133
.github/CODE_OF_CONDUCT.md
vendored
Normal file
133
.github/CODE_OF_CONDUCT.md
vendored
Normal file
@@ -0,0 +1,133 @@
|
||||
|
||||
# Contributor Covenant Code of Conduct
|
||||
|
||||
## Our Pledge
|
||||
|
||||
We as members, contributors, and leaders pledge to make participation in our
|
||||
community a harassment-free experience for everyone, regardless of age, body
|
||||
size, visible or invisible disability, ethnicity, sex characteristics, gender
|
||||
identity and expression, level of experience, education, socio-economic status,
|
||||
nationality, personal appearance, race, religion, or sexual identity
|
||||
and orientation.
|
||||
|
||||
We pledge to act and interact in ways that contribute to an open, welcoming,
|
||||
diverse, inclusive, and healthy community.
|
||||
|
||||
## Our Standards
|
||||
|
||||
Examples of behavior that contributes to a positive environment for our
|
||||
community include:
|
||||
|
||||
* Demonstrating empathy and kindness toward other people
|
||||
* Being respectful of differing opinions, viewpoints, and experiences
|
||||
* Giving and gracefully accepting constructive feedback
|
||||
* Accepting responsibility and apologizing to those affected by our mistakes,
|
||||
and learning from the experience
|
||||
* Focusing on what is best not just for us as individuals, but for the
|
||||
overall community
|
||||
|
||||
Examples of unacceptable behavior include:
|
||||
|
||||
* The use of sexualized language or imagery, and sexual attention or
|
||||
advances of any kind
|
||||
* Trolling, insulting or derogatory comments, and personal or political attacks
|
||||
* Public or private harassment
|
||||
* Publishing others' private information, such as a physical or email
|
||||
address, without their explicit permission
|
||||
* Other conduct which could reasonably be considered inappropriate in a
|
||||
professional setting
|
||||
|
||||
## Enforcement Responsibilities
|
||||
|
||||
Community leaders are responsible for clarifying and enforcing our standards of
|
||||
acceptable behavior and will take appropriate and fair corrective action in
|
||||
response to any behavior that they deem inappropriate, threatening, offensive,
|
||||
or harmful.
|
||||
|
||||
Community leaders have the right and responsibility to remove, edit, or reject
|
||||
comments, commits, code, wiki edits, issues, and other contributions that are
|
||||
not aligned to this Code of Conduct, and will communicate reasons for moderation
|
||||
decisions when appropriate.
|
||||
|
||||
## Scope
|
||||
|
||||
This Code of Conduct applies within all community spaces, and also applies when
|
||||
an individual is officially representing the community in public spaces.
|
||||
Examples of representing our community include using an official e-mail address,
|
||||
posting via an official social media account, or acting as an appointed
|
||||
representative at an online or offline event.
|
||||
|
||||
## Enforcement
|
||||
|
||||
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
||||
reported to the community leaders responsible for enforcement at
|
||||
[INSERT CONTACT METHOD].
|
||||
All complaints will be reviewed and investigated promptly and fairly.
|
||||
|
||||
All community leaders are obligated to respect the privacy and security of the
|
||||
reporter of any incident.
|
||||
|
||||
## Enforcement Guidelines
|
||||
|
||||
Community leaders will follow these Community Impact Guidelines in determining
|
||||
the consequences for any action they deem in violation of this Code of Conduct:
|
||||
|
||||
### 1. Correction
|
||||
|
||||
**Community Impact**: Use of inappropriate language or other behavior deemed
|
||||
unprofessional or unwelcome in the community.
|
||||
|
||||
**Consequence**: A private, written warning from community leaders, providing
|
||||
clarity around the nature of the violation and an explanation of why the
|
||||
behavior was inappropriate. A public apology may be requested.
|
||||
|
||||
### 2. Warning
|
||||
|
||||
**Community Impact**: A violation through a single incident or series
|
||||
of actions.
|
||||
|
||||
**Consequence**: A warning with consequences for continued behavior. No
|
||||
interaction with the people involved, including unsolicited interaction with
|
||||
those enforcing the Code of Conduct, for a specified period of time. This
|
||||
includes avoiding interactions in community spaces as well as external channels
|
||||
like social media. Violating these terms may lead to a temporary or
|
||||
permanent ban.
|
||||
|
||||
### 3. Temporary Ban
|
||||
|
||||
**Community Impact**: A serious violation of community standards, including
|
||||
sustained inappropriate behavior.
|
||||
|
||||
**Consequence**: A temporary ban from any sort of interaction or public
|
||||
communication with the community for a specified period of time. No public or
|
||||
private interaction with the people involved, including unsolicited interaction
|
||||
with those enforcing the Code of Conduct, is allowed during this period.
|
||||
Violating these terms may lead to a permanent ban.
|
||||
|
||||
### 4. Permanent Ban
|
||||
|
||||
**Community Impact**: Demonstrating a pattern of violation of community
|
||||
standards, including sustained inappropriate behavior, harassment of an
|
||||
individual, or aggression toward or disparagement of classes of individuals.
|
||||
|
||||
**Consequence**: A permanent ban from any sort of public interaction within
|
||||
the community.
|
||||
|
||||
## Attribution
|
||||
|
||||
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
||||
version 2.0, available at
|
||||
[https://www.contributor-covenant.org/version/2/0/code_of_conduct.html][v2.0].
|
||||
|
||||
Community Impact Guidelines were inspired by
|
||||
[Mozilla's code of conduct enforcement ladder][Mozilla CoC].
|
||||
|
||||
For answers to common questions about this code of conduct, see the FAQ at
|
||||
[https://www.contributor-covenant.org/faq][FAQ]. Translations are available
|
||||
at [https://www.contributor-covenant.org/translations][translations].
|
||||
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
[v2.0]: https://www.contributor-covenant.org/version/2/0/code_of_conduct.html
|
||||
[Mozilla CoC]: https://github.com/mozilla/diversity
|
||||
[FAQ]: https://www.contributor-covenant.org/faq
|
||||
[translations]: https://www.contributor-covenant.org/translations
|
||||
0
.github/CONTRIBUTING.md
vendored
Normal file
0
.github/CONTRIBUTING.md
vendored
Normal file
44
.github/workflows/ci.yml
vendored
Normal file
44
.github/workflows/ci.yml
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
name: Test & QA
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
pull_request:
|
||||
branches:
|
||||
- main
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ['3.8', '3.9', '3.10', '3.11']
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python ${{ matrix.python-version }}
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install -r requirements.txt
|
||||
|
||||
- name: Lint
|
||||
run: |
|
||||
pip install flake8 ruff
|
||||
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
|
||||
# stop the build if there are Python syntax errors or undefined names
|
||||
ruff --format=github --select=E9,F63,F7,F82 --target-version=py37 .
|
||||
# default set of ruff rules with GitHub Annotations
|
||||
#ruff --format=github --target-version=py37 --ignore=F401,E501 .
|
||||
|
||||
- name: Run tests
|
||||
run: |
|
||||
pip install pytest
|
||||
cd pilot
|
||||
PYTHONPATH=. pytest
|
||||
338
.gitignore
vendored
338
.gitignore
vendored
@@ -1,167 +1,171 @@
|
||||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
wheels/
|
||||
share/python-wheels/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.nox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*.cover
|
||||
*.py,cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
cover/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
db.sqlite3-journal
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
docs/_build/
|
||||
|
||||
# PyBuilder
|
||||
.pybuilder/
|
||||
target/
|
||||
|
||||
# Jupyter Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# IPython
|
||||
profile_default/
|
||||
ipython_config.py
|
||||
|
||||
# pyenv
|
||||
# For a library or package, you might want to ignore these files since the code is
|
||||
# intended to run in multiple environments; otherwise, check them in:
|
||||
# .python-version
|
||||
|
||||
# pipenv
|
||||
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
||||
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
||||
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
||||
# install all needed dependencies.
|
||||
#Pipfile.lock
|
||||
|
||||
# poetry
|
||||
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
||||
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
||||
# commonly ignored for libraries.
|
||||
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
||||
#poetry.lock
|
||||
|
||||
# pdm
|
||||
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
||||
#pdm.lock
|
||||
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
||||
# in version control.
|
||||
# https://pdm.fming.dev/#use-with-ide
|
||||
.pdm.toml
|
||||
|
||||
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
||||
__pypackages__/
|
||||
|
||||
# Celery stuff
|
||||
celerybeat-schedule
|
||||
celerybeat.pid
|
||||
|
||||
# SageMath parsed files
|
||||
*.sage.py
|
||||
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
env.bak/
|
||||
venv.bak/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
.spyproject
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# mkdocs documentation
|
||||
/site
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
.dmypy.json
|
||||
dmypy.json
|
||||
|
||||
# Pyre type checker
|
||||
.pyre/
|
||||
|
||||
# pytype static type analyzer
|
||||
.pytype/
|
||||
|
||||
# Cython debug symbols
|
||||
cython_debug/
|
||||
|
||||
# PyCharm
|
||||
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
||||
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
||||
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
||||
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
||||
.idea/
|
||||
|
||||
|
||||
# Logger
|
||||
/pilot/logger/debug.log
|
||||
|
||||
# workspace
|
||||
workspace
|
||||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
wheels/
|
||||
share/python-wheels/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.nox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*.cover
|
||||
*.py,cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
cover/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
db.sqlite3-journal
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
docs/_build/
|
||||
|
||||
# PyBuilder
|
||||
.pybuilder/
|
||||
target/
|
||||
|
||||
# Jupyter Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# IPython
|
||||
profile_default/
|
||||
ipython_config.py
|
||||
|
||||
# pyenv
|
||||
# For a library or package, you might want to ignore these files since the code is
|
||||
# intended to run in multiple environments; otherwise, check them in:
|
||||
# .python-version
|
||||
|
||||
# pipenv
|
||||
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
||||
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
||||
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
||||
# install all needed dependencies.
|
||||
#Pipfile.lock
|
||||
|
||||
# poetry
|
||||
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
||||
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
||||
# commonly ignored for libraries.
|
||||
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
||||
#poetry.lock
|
||||
|
||||
# pdm
|
||||
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
||||
#pdm.lock
|
||||
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
||||
# in version control.
|
||||
# https://pdm.fming.dev/#use-with-ide
|
||||
.pdm.toml
|
||||
|
||||
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
||||
__pypackages__/
|
||||
|
||||
# Celery stuff
|
||||
celerybeat-schedule
|
||||
celerybeat.pid
|
||||
|
||||
# SageMath parsed files
|
||||
*.sage.py
|
||||
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
env.bak/
|
||||
venv.bak/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
.spyproject
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# mkdocs documentation
|
||||
/site
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
.dmypy.json
|
||||
dmypy.json
|
||||
|
||||
# Pyre type checker
|
||||
.pyre/
|
||||
|
||||
# pytype static type analyzer
|
||||
.pytype/
|
||||
|
||||
# Cython debug symbols
|
||||
cython_debug/
|
||||
|
||||
# PyCharm
|
||||
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
||||
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
||||
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
||||
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
||||
.idea/
|
||||
|
||||
|
||||
# Logger
|
||||
/pilot/logger/debug.log
|
||||
|
||||
#sqlite
|
||||
/pilot/gpt-pilot
|
||||
|
||||
# workspace
|
||||
workspace
|
||||
pilot-env/
|
||||
|
||||
214
LICENSE
214
LICENSE
@@ -1,201 +1,21 @@
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
MIT License
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
Copyright (c) 2023 Pythagora-io
|
||||
|
||||
1. Definitions.
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright [yyyy] [name of copyright owner]
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
|
||||
131
README.md
131
README.md
@@ -1,54 +1,77 @@
|
||||
# 🧑✈️ GPT PILOT
|
||||
### GPT Pilot can code out the entire app as you oversee the code being written
|
||||
This is our try to see how can GPT-4 be utilized to generate working apps and to my surprise, it works quite well.
|
||||
|
||||
**Detailed explanation about the concept behind GPT Pilot can be found in [this blog post](https://blog.pythagora.ai/2023/08/23/430/).**
|
||||
### GPT Pilot helps developers build apps 20x faster
|
||||
|
||||
---
|
||||
|
||||
<!-- TOC -->
|
||||
* [Main pillars of GPT Pilot:](#main-pillars-of-gpt-pilot)
|
||||
* [Requirements](#requirements)
|
||||
* [🚦How to start using gpt-pilot?](#how-to-start-using-gpt-pilot)
|
||||
* [🧑💻️ Other arguments](#-other-arguments)
|
||||
* [🔎 Examples](#-examples)
|
||||
* [Real-time chat app](#real-time-chat-app)
|
||||
* [Markdown editor](#markdown-editor)
|
||||
* [Timer app](#timer-app)
|
||||
* [Real-time chat app](#-real-time-chat-app)
|
||||
* [Markdown editor](#-markdown-editor)
|
||||
* [Timer app](#%EF%B8%8F-timer-app)
|
||||
* [🏛 Main pillars of GPT Pilot](#main-pillars-of-gpt-pilot)
|
||||
* [🏗 How GPT Pilot works?](#-how-gpt-pilot-works)
|
||||
* [🕴How's GPT Pilot different from _Smol developer_ and _GPT engineer_?](#hows-gpt-pilot-different-from-smol-developer-and-gpt-engineer)
|
||||
* [🍻 Contributing](#-contributing)
|
||||
* [🔗 Connect with us](#-connect-with-us)
|
||||
<!-- TOC -->
|
||||
|
||||
---
|
||||
|
||||
## Main pillars of GPT Pilot:
|
||||
1. For AI to create a fully working app, **a developer needs to be involved** in the process of app creation. They need to be able to change the code at any moment and GPT Pilot needs to continue working with those changes (eg. add an API key or fix an issue if an AI gets stuck) <br><br>
|
||||
2. **The app needs to be written step by step as a developer would write it** - Let's say you want to create a simple app and you know everything you need to code and have the entire architecture in your head. Even then, you won't code it out entirely, then run it for the first time and debug all the issues at once. Rather, you will implement something simple, like add routes, run it, see how it works, and then move on to the next task. This way, you can debug issues as they arise. The same should be in the case when AI codes. It will make mistakes for sure so in order for it to have an easier time debugging issues and for the developer to understand what is happening, the AI shouldn't just spit out the entire codebase at once. Rather, the app should be developed step by step just like a developer would code it - eg. setup routes, add database connection, etc. <br><br>
|
||||
3. **The approach needs to be scalable** so that AI can create a production ready app
|
||||
1. **Context rewinding** - for solving each development task, the context size of the first message to the LLM has to be relatively the same. For example, the context size of the first LLM message while implementing development task #5 has to be more or less the same as the first message while developing task #50. Because of this, the conversation needs to be rewound to the first message upon each task. [See the diagram here](https://blogpythagora.files.wordpress.com/2023/08/pythagora-product-development-frame-3-1.jpg?w=1714).
|
||||
2. **Recursive conversations** are LLM conversations that are set up in a way that they can be used “recursively”. For example, if GPT Pilot detects an error, it needs to debug it but let’s say that, during the debugging process, another error happens. Then, GPT Pilot needs to stop debugging the first issue, fix the second one, and then get back to fixing the first issue. This is a very important concept that, I believe, needs to work to make AI build large and scalable apps by itself. It works by rewinding the context and explaining each error in the recursion separately. Once the deepest level error is fixed, we move up in the recursion and continue fixing that error. We do this until the entire recursion is completed.
|
||||
3. **TDD (Test Driven Development)** - for GPT Pilot to be able to scale the codebase, it will need to be able to create new code without breaking previously written code. There is no better way to do this than working with TDD methodology. For each code that GPT Pilot writes, it needs to write tests that check if the code works as intended so that whenever new changes are made, all previous tests can be run.
|
||||
The goal of GPT Pilot is to research how much can GPT-4 be utilized to generate fully working, production-ready apps while the developer oversees the implementation.
|
||||
|
||||
The idea is that AI won't be able to (at least in the near future) create apps from scratch without the developer being involved. That's why we created an interactive tool that generates code but also requires the developer to check each step so that they can understand what's going on and so that the AI can have a better overview of the entire codebase.
|
||||
**The main idea is that AI can write most of the code for an app (maybe 95%) but for the rest 5%, a developer is and will be needed until we get full AGI**.
|
||||
|
||||
Obviously, it still can't create any production-ready app but the general concept of how this could work is there.
|
||||
I've broken down the idea behind GPT Pilot and how it works in the following blog posts:
|
||||
|
||||
**[[Part 1/3] High-level concepts + GPT Pilot workflow until the coding part](https://blog.pythagora.ai/2023/08/23/430/)**
|
||||
|
||||
**_[Part 2/3] GPT Pilot coding workflow (COMING UP)_**
|
||||
|
||||
**_[Part 3/3] Other important concepts and future plans (COMING UP)_**
|
||||
|
||||
---
|
||||
|
||||
|
||||
<div align="center">
|
||||
|
||||
### **[👉 Examples of apps written by GPT Pilot 👈](#-examples)**
|
||||
|
||||
</div>
|
||||
|
||||
<br>
|
||||
|
||||
https://github.com/Pythagora-io/gpt-pilot/assets/10895136/0495631b-511e-451b-93d5-8a42acf22d3d
|
||||
|
||||
# 🔌 Requirements
|
||||
|
||||
|
||||
- **Python**
|
||||
- **PostgreSQL** (optional, projects default is SQLite)
|
||||
- DB is needed for multiple reasons like continuing app development if you had to stop at any point or app crashed, going back to specific step so you can change some later steps in development, easier debugging, for future we will add functionality to update project (change some things in existing project or add new features to the project and so on)...
|
||||
|
||||
[See examples of apps written by GPT Pilot here](#-examples)
|
||||
|
||||
# 🚦How to start using gpt-pilot?
|
||||
1. Clone the repo
|
||||
After you have Python and PostgreSQL installed, follow these steps:
|
||||
1. `git clone https://github.com/Pythagora-io/gpt-pilot.git` (clone the repo)
|
||||
2. `cd gpt-pilot`
|
||||
3. `python -m venv pilot-env`
|
||||
4. `source pilot-env/bin/activate`
|
||||
5. `pip install -r requirements.txt`
|
||||
3. `python -m venv pilot-env` (create a virtual environment)
|
||||
4. `source pilot-env/bin/activate` (activate the virtual environment)
|
||||
5. `pip install -r requirements.txt` (install the dependencies)
|
||||
6. `cd pilot`
|
||||
7. `mv .env.example .env`
|
||||
8. Add your OpenAI API key and the database info to the `.env` file
|
||||
9. `python main.py`
|
||||
7. `mv .env.example .env` (create the .env file)
|
||||
8. Add your environment (OpenAI/Azure), your API key and the SQLite/PostgreSQL database info to the `.env` file
|
||||
- to change from SQLite to PostgreSQL in your .env just set `DATABASE_TYPE=postgres`
|
||||
9. `python db_init.py` (initialize the database)
|
||||
10. `python main.py` (start GPT Pilot)
|
||||
|
||||
After, this, you can just follow the instructions in the terminal.
|
||||
|
||||
All generated code will be stored in the folder `workspace` inside the folder named after the app name you enter upon starting the pilot.
|
||||
|
||||
**IMPORTANT: To run GPT Pilot, you need to have PostgreSQL set up on your machine**
|
||||
<br>
|
||||
|
||||
# 🧑💻️ Other arguments
|
||||
@@ -66,41 +89,47 @@ python main.py app_id=<ID_OF_THE_APP> step=<STEP_FROM_CONST_COMMON>
|
||||
```bash
|
||||
python main.py app_id=<ID_OF_THE_APP> skip_until_dev_step=<DEV_STEP>
|
||||
```
|
||||
This is basically the same as `step` but during the actual development process. If you want to play around with gpt-pilot, this is likely the flag you will often use
|
||||
This is basically the same as `step` but during the actual development process. If you want to play around with gpt-pilot, this is likely the flag you will often use.
|
||||
<br>
|
||||
- erase all development steps previously done and continue working on an existing app from start of development
|
||||
```bash
|
||||
python main.py app_id=<ID_OF_THE_APP> skip_until_dev_step=0
|
||||
```
|
||||
|
||||
# 🔎 Examples
|
||||
|
||||
Here are a couple of example apps GPT Pilot created by itself:
|
||||
|
||||
### Real-time chat app
|
||||
### 📱 Real-time chat app
|
||||
- 💬 Prompt: `A simple chat app with real time communication`
|
||||
- ▶️ [Video of the app creation process](https://youtu.be/bUj9DbMRYhA)
|
||||
- 💻️ [Github repo](https://github.com/Pythagora-io/gpt-pilot-chat-app-demo)
|
||||
|
||||
<p align="left">
|
||||
<img src="https://github.com/Pythagora-io/gpt-pilot/assets/10895136/85bc705c-be88-4ca1-9a3b-033700b97a22" alt="gpt-pilot demo chat app" width="500px"/>
|
||||
</p>
|
||||
- 💻️ [GitHub repo](https://github.com/Pythagora-io/gpt-pilot-chat-app-demo)
|
||||
|
||||
|
||||
### Markdown editor
|
||||
### 📝 Markdown editor
|
||||
- 💬 Prompt: `Build a simple markdown editor using HTML, CSS, and JavaScript. Allow users to input markdown text and display the formatted output in real-time.`
|
||||
- ▶️ [Video of the app creation process](https://youtu.be/uZeA1iX9dgg)
|
||||
- 💻️ [Github repo](https://github.com/Pythagora-io/gpt-pilot-demo-markdown-editor.git)
|
||||
|
||||
<p align="left">
|
||||
<img src="https://github.com/Pythagora-io/gpt-pilot/assets/10895136/dbe1ccc3-b126-4df0-bddb-a524d6a386a8" alt="gpt-pilot demo markdown editor" width="500px"/>
|
||||
</p>
|
||||
- 💻️ [GitHub repo](https://github.com/Pythagora-io/gpt-pilot-demo-markdown-editor.git)
|
||||
|
||||
|
||||
### Timer app
|
||||
### ⏱️ Timer app
|
||||
- 💬 Prompt: `Create a simple timer app using HTML, CSS, and JavaScript that allows users to set a countdown timer and receive an alert when the time is up.`
|
||||
- ▶️ [Video of the app creation process](https://youtu.be/CMN3W18zfiE)
|
||||
- 💻️ [Github repo](https://github.com/Pythagora-io/gpt-pilot-timer-app-demo)
|
||||
- 💻️ [GitHub repo](https://github.com/Pythagora-io/gpt-pilot-timer-app-demo)
|
||||
|
||||
<p align="left">
|
||||
<img src="https://github.com/Pythagora-io/gpt-pilot/assets/10895136/93bed40b-b769-4c8b-b16d-b80fb6fc73e0" alt="gpt-pilot demo markdown editor" width="500px"/>
|
||||
</p>
|
||||
<br>
|
||||
|
||||
# 🏛 Main pillars of GPT Pilot:
|
||||
1. For AI to create a fully working app, **a developer needs to be involved** in the process of app creation. They need to be able to change the code at any moment and GPT Pilot needs to continue working with those changes (eg. add an API key or fix an issue if an AI gets stuck) <br><br>
|
||||
2. **The app needs to be written step by step as a developer would write it** - Let's say you want to create a simple app and you know everything you need to code and have the entire architecture in your head. Even then, you won't code it out entirely, then run it for the first time and debug all the issues at once. Rather, you will implement something simple, like add routes, run it, see how it works, and then move on to the next task. This way, you can debug issues as they arise. The same should be in the case when AI codes. It will make mistakes for sure so in order for it to have an easier time debugging issues and for the developer to understand what is happening, the AI shouldn't just spit out the entire codebase at once. Rather, the app should be developed step by step just like a developer would code it - eg. setup routes, add database connection, etc. <br><br>
|
||||
3. **The approach needs to be scalable** so that AI can create a production ready app
|
||||
1. **Context rewinding** - for solving each development task, the context size of the first message to the LLM has to be relatively the same. For example, the context size of the first LLM message while implementing development task #5 has to be more or less the same as the first message while developing task #50. Because of this, the conversation needs to be rewound to the first message upon each task. [See the diagram here](https://blogpythagora.files.wordpress.com/2023/08/pythagora-product-development-frame-3-1.jpg?w=1714).
|
||||
2. **Recursive conversations** are LLM conversations that are set up in a way that they can be used “recursively”. For example, if GPT Pilot detects an error, it needs to debug it but let’s say that, during the debugging process, another error happens. Then, GPT Pilot needs to stop debugging the first issue, fix the second one, and then get back to fixing the first issue. This is a very important concept that, I believe, needs to work to make AI build large and scalable apps by itself. It works by rewinding the context and explaining each error in the recursion separately. Once the deepest level error is fixed, we move up in the recursion and continue fixing that error. We do this until the entire recursion is completed.
|
||||
3. **TDD (Test Driven Development)** - for GPT Pilot to be able to scale the codebase, it will need to be able to create new code without breaking previously written code. There is no better way to do this than working with TDD methodology. For each code that GPT Pilot writes, it needs to write tests that check if the code works as intended so that whenever new changes are made, all previous tests can be run.
|
||||
|
||||
The idea is that AI won't be able to (at least in the near future) create apps from scratch without the developer being involved. That's why we created an interactive tool that generates code but also requires the developer to check each step so that they can understand what's going on and so that the AI can have a better overview of the entire codebase.
|
||||
|
||||
Obviously, it still can't create any production-ready app but the general concept of how this could work is there.
|
||||
|
||||
# 🏗 How GPT Pilot works?
|
||||
Here are the steps GPT Pilot takes to create an app:
|
||||
@@ -116,19 +145,31 @@ Here are the steps GPT Pilot takes to create an app:
|
||||
7. **Developer agent** takes each task and writes up what needs to be done to implement it. The description is in human readable form.
|
||||
8. Finally, **Code Monkey agent** takes the Developer's description and the currently implement file and implements the changes into it. We realized this works much better than giving it to Developer right away to implement changes.
|
||||
|
||||

|
||||
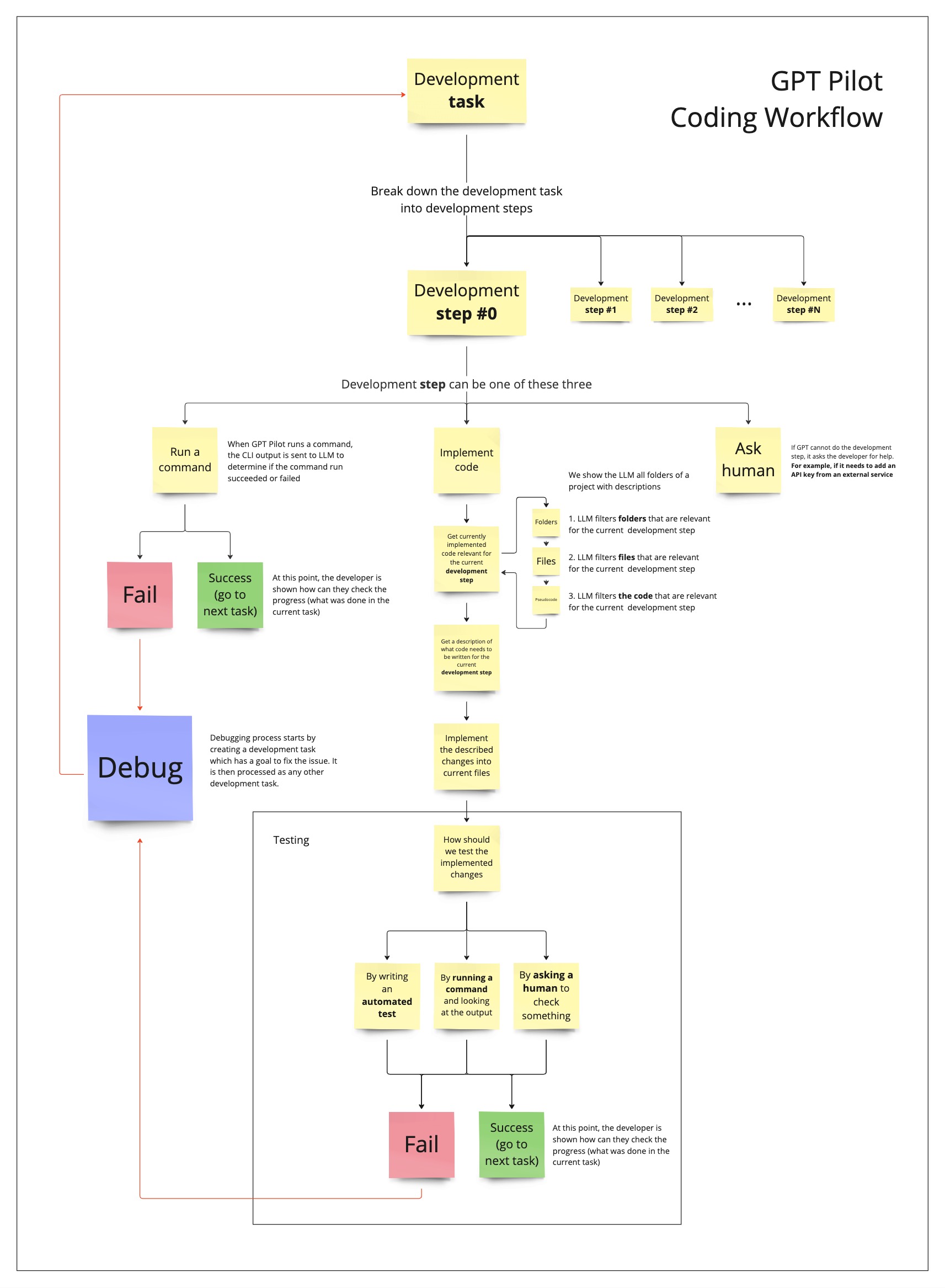
|
||||
|
||||
|
||||
<br>
|
||||
|
||||
# 🕴How's GPT Pilot different from _Smol developer_ and _GPT engineer_?
|
||||
- **Human developer is involved throughout the process** - I don't think that AI can't (at least in the near future) create apps without a developer being involved. Also, I think it's hard for a developer to get into a big codebase and try debugging it. That's why my idea was for AI to develop the app step by step where each step is reviewed by the developer. If you want to change some code yourself, you can just change it and GPT Pilot will continue developing on top of those changes.
|
||||
- **Human developer is involved throughout the process** - I don't think that AI can (at least in the near future) create apps without a developer being involved. Also, I think it's hard for a developer to get into a big codebase and try debugging it. That's why my idea was for AI to develop the app step by step where each step is reviewed by the developer. If you want to change some code yourself, you can just change it and GPT Pilot will continue developing on top of those changes.
|
||||
<br><br>
|
||||
- **Continuous development loops** - The goal behind this project was to see how we can create recursive conversations with GPT so that it can debug any issue and implement any feature. For example, after the app is generated, you can always add more instructions about what you want to implement or debug. I wanted to see if this can be so flexible that, regardless of the app's size, it can just iterate and build bigger and bigger apps
|
||||
<br><br>
|
||||
- **Auto debugging** - when it detects an error, it debugs it by itself. I still haven't implemented writing automated tests which should make this fully autonomous but for now, you can input the error that's happening (eg. within a UI) and GPT Pilot will debug it from there. The plan is to make it write automated tests in Cypress as well so that it can test it by itself and debug without the developer's explanation.
|
||||
|
||||
# 🍻 Contributing
|
||||
If you are interested in contributing to GPT Pilot, I would be more than happy to have you on board but also help you get started. Feel free to ping [zvonimir@pythagora.ai](mailto:zvonimir@pythagora.ai) and I'll help you get started.
|
||||
|
||||
## 🔬️ Research
|
||||
Since this is a research project, there are many areas that need to be researched on both practical and theoretical levels. We're happy to hear how can the entire GPT Pilot concept be improved. For example, maybe it would work better if we structured functional requirements differently or maybe technical requirements need to be specified in a different way.
|
||||
|
||||
## 🖥 Development
|
||||
Other than the research, GPT Pilot needs to be debugged to work in different scenarios. For example, we realized that the quality of the code generated is very sensitive to the size of the development task. When the task is too broad, the code has too many bugs that are hard to fix but when the development task is too narrow, GPT also seems to struggle in getting the task implemented into the existing code.
|
||||
|
||||
# 🔗 Connect with us
|
||||
🌟 As an open source tool, it would mean the world to us if you starred the GPT-pilot repo 🌟
|
||||
|
||||
💬 Join [the Discord server](https://discord.gg/HaqXugmxr9) to get in touch.
|
||||
<br><br>
|
||||
<br><br>
|
||||
|
||||
|
||||
@@ -1,4 +1,11 @@
|
||||
#OPENAI or AZURE
|
||||
ENDPOINT=OPENAI
|
||||
OPENAI_API_KEY=
|
||||
AZURE_API_KEY=
|
||||
AZURE_ENDPOINT=
|
||||
#In case of Azure endpoint, change this to your deployed model name
|
||||
MODEL_NAME=gpt-4
|
||||
MAX_TOKENS=8192
|
||||
DB_NAME=gpt-pilot
|
||||
DB_HOST=localhost
|
||||
DB_PORT=5432
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
APP_TYPES = ['Web App', 'Script', 'Mobile App (unavailable)', 'Chrome Extension (unavailable)']
|
||||
APP_TYPES = ['Web App', 'Script', 'Mobile App', 'Chrome Extension']
|
||||
ROLES = {
|
||||
'product_owner': ['project_description', 'user_stories', 'user_tasks'],
|
||||
'architect': ['architecture'],
|
||||
|
||||
@@ -40,7 +40,7 @@ def return_array_from_prompt(name_plural, name_singular, return_var_name):
|
||||
}
|
||||
|
||||
|
||||
def command_definition(description_command=f'A single command that needs to be executed.', description_timeout=f'Timeout in milliseconds that represent the approximate time this command takes to finish. If you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds.'):
|
||||
def command_definition(description_command=f'A single command that needs to be executed.', description_timeout=f'Timeout in milliseconds that represent the approximate time this command takes to finish. If you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds. If you need to create a directory that doesn\'t exist and is not the root project directory, always create it by running a command `mkdir`'):
|
||||
return {
|
||||
'type': 'object',
|
||||
'description': 'Command that needs to be run to complete the current task. This should be used only if the task is of a type "command".',
|
||||
@@ -125,7 +125,7 @@ DEV_TASKS_BREAKDOWN = {
|
||||
'description': 'List of smaller development steps that need to be done to complete the entire task.',
|
||||
'items': {
|
||||
'type': 'object',
|
||||
'description': 'A smaller development step that needs to be done to complete the entire task. Remember, if you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds.',
|
||||
'description': 'A smaller development step that needs to be done to complete the entire task. Remember, if you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds. If you need to create a directory that doesn\'t exist and is not the root project directory, always create it by running a command `mkdir`',
|
||||
'properties': {
|
||||
'type': {
|
||||
'type': 'string',
|
||||
@@ -168,11 +168,11 @@ IMPLEMENT_TASK = {
|
||||
'description': 'List of smaller development steps that need to be done to complete the entire task.',
|
||||
'items': {
|
||||
'type': 'object',
|
||||
'description': 'A smaller development step that needs to be done to complete the entire task. Remember, if you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds.',
|
||||
'description': 'A smaller development step that needs to be done to complete the entire task. Remember, if you need to run a command that doesnt\'t finish by itself (eg. a command to run an If you need to create a directory that doesn\'t exist and is not the root project directory, always create it by running a command `mkdir`',
|
||||
'properties': {
|
||||
'type': {
|
||||
'type': 'string',
|
||||
'enum': ['command', 'code_change', 'human_invervention'],
|
||||
'enum': ['command', 'code_change', 'human_intervention'],
|
||||
'description': 'Type of the development step that needs to be done to complete the entire task.',
|
||||
},
|
||||
'command': command_definition(),
|
||||
@@ -316,7 +316,7 @@ CODE_CHANGES = {
|
||||
'description': 'List of smaller development steps that need to be done to complete the entire task.',
|
||||
'items': {
|
||||
'type': 'object',
|
||||
'description': 'A smaller development step that needs to be done to complete the entire task. Remember, if you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds.',
|
||||
'description': 'A smaller development step that needs to be done to complete the entire task. Remember, if you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds. If you need to create a directory that doesn\'t exist and is not the root project directory, always create it by running a command `mkdir`',
|
||||
'properties': {
|
||||
'type': {
|
||||
'type': 'string',
|
||||
@@ -390,7 +390,7 @@ EXECUTE_COMMANDS = {
|
||||
'properties': {
|
||||
'commands': {
|
||||
'type': 'array',
|
||||
'description': f'List of commands that need to be executed. Remember, if you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds.',
|
||||
'description': f'List of commands that need to be executed. Remember, if you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds. If you need to create a directory that doesn\'t exist and is not the root project directory, always create it by running a command `mkdir`',
|
||||
'items': command_definition(f'A single command that needs to be executed.', f'Timeout in milliseconds that represent the approximate time this command takes to finish. If you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds.')
|
||||
}
|
||||
},
|
||||
@@ -483,7 +483,7 @@ GET_TEST_TYPE = {
|
||||
'description': f'Type of a test that needs to be run. If this is just an intermediate step in getting a task done, put `no_test` as the type and we\'ll just go onto the next task without testing.',
|
||||
'enum': ['automated_test', 'command_test', 'manual_test', 'no_test']
|
||||
},
|
||||
'command': command_definition('Command that needs to be run to test the changes.', 'Timeout in milliseconds that represent the approximate time this command takes to finish. If you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds.'),
|
||||
'command': command_definition('Command that needs to be run to test the changes.', 'Timeout in milliseconds that represent the approximate time this command takes to finish. If you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds. If you need to create a directory that doesn\'t exist and is not the root project directory, always create it by running a command `mkdir`'),
|
||||
'automated_test_description': {
|
||||
'type': 'string',
|
||||
'description': 'Description of an automated test that needs to be run to test the changes. This should be used only if the test type is "automated_test" and it should thoroughly describe what needs to be done to implement the automated test so that when someone looks at this test can know exactly what needs to be done to implement this automated test.',
|
||||
@@ -515,7 +515,7 @@ DEBUG_STEPS_BREAKDOWN = {
|
||||
'description': 'List of steps that need to be done to debug the problem.',
|
||||
'items': {
|
||||
'type': 'object',
|
||||
'description': 'A single step that needs to be done to get closer to debugging this issue. Remember, if you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds.',
|
||||
'description': 'A single step that needs to be done to get closer to debugging this issue. Remember, if you need to run a command that doesnt\'t finish by itself (eg. a command to run an app), put the timeout to 3000 milliseconds. If you need to create a directory that doesn\'t exist and is not the root project directory, always create it by running a command `mkdir`',
|
||||
'properties': {
|
||||
'type': {
|
||||
'type': 'string',
|
||||
|
||||
@@ -1,4 +1,5 @@
|
||||
import os
|
||||
MAX_GPT_MODEL_TOKENS = int(os.getenv('MAX_TOKENS', 8192))
|
||||
MIN_TOKENS_FOR_GPT_RESPONSE = 600
|
||||
MAX_GPT_MODEL_TOKENS = 8192
|
||||
MAX_QUESTIONS = 5
|
||||
END_RESPONSE = "EVERYTHING_CLEAR"
|
||||
END_RESPONSE = "EVERYTHING_CLEAR"
|
||||
8
pilot/database/config.py
Normal file
8
pilot/database/config.py
Normal file
@@ -0,0 +1,8 @@
|
||||
import os
|
||||
|
||||
DATABASE_TYPE = os.getenv("DATABASE_TYPE", "sqlite")
|
||||
DB_NAME = os.getenv("DB_NAME")
|
||||
DB_HOST = os.getenv("DB_HOST")
|
||||
DB_PORT = os.getenv("DB_PORT")
|
||||
DB_USER = os.getenv("DB_USER")
|
||||
DB_PASSWORD = os.getenv("DB_PASSWORD")
|
||||
22
pilot/database/connection/postgres.py
Normal file
22
pilot/database/connection/postgres.py
Normal file
@@ -0,0 +1,22 @@
|
||||
import psycopg2
|
||||
from peewee import PostgresqlDatabase
|
||||
from psycopg2.extensions import quote_ident
|
||||
from database.config import DB_NAME, DB_HOST, DB_PORT, DB_USER, DB_PASSWORD
|
||||
|
||||
def get_postgres_database():
|
||||
return PostgresqlDatabase(DB_NAME, user=DB_USER, password=DB_PASSWORD, host=DB_HOST, port=DB_PORT)
|
||||
|
||||
def create_postgres_database():
|
||||
conn = psycopg2.connect(
|
||||
dbname='postgres',
|
||||
user=DB_USER,
|
||||
password=DB_PASSWORD,
|
||||
host=DB_HOST,
|
||||
port=DB_PORT
|
||||
)
|
||||
conn.autocommit = True
|
||||
cursor = conn.cursor()
|
||||
safe_db_name = quote_ident(DB_NAME, conn)
|
||||
cursor.execute(f"CREATE DATABASE {safe_db_name}")
|
||||
cursor.close()
|
||||
conn.close()
|
||||
5
pilot/database/connection/sqlite.py
Normal file
5
pilot/database/connection/sqlite.py
Normal file
@@ -0,0 +1,5 @@
|
||||
from peewee import SqliteDatabase
|
||||
from database.config import DB_NAME
|
||||
|
||||
def get_sqlite_database():
|
||||
return SqliteDatabase(DB_NAME)
|
||||
@@ -4,12 +4,12 @@ from termcolor import colored
|
||||
from functools import reduce
|
||||
import operator
|
||||
import psycopg2
|
||||
import os
|
||||
from const.common import PROMPT_DATA_TO_IGNORE
|
||||
from logger.logger import logger
|
||||
from psycopg2.extensions import quote_ident
|
||||
|
||||
from const.common import PROMPT_DATA_TO_IGNORE
|
||||
from logger.logger import logger
|
||||
from utils.utils import hash_data
|
||||
from database.config import DB_NAME, DB_HOST, DB_PORT, DB_USER, DB_PASSWORD, DATABASE_TYPE
|
||||
from database.models.components.base_models import database
|
||||
from database.models.user import User
|
||||
from database.models.app import App
|
||||
@@ -23,15 +23,10 @@ from database.models.environment_setup import EnvironmentSetup
|
||||
from database.models.development import Development
|
||||
from database.models.file_snapshot import FileSnapshot
|
||||
from database.models.command_runs import CommandRuns
|
||||
from database.models.user_apps import UserApps
|
||||
from database.models.user_inputs import UserInputs
|
||||
from database.models.files import File
|
||||
|
||||
DB_NAME = os.getenv("DB_NAME")
|
||||
DB_HOST = os.getenv("DB_HOST")
|
||||
DB_PORT = os.getenv("DB_PORT")
|
||||
DB_USER = os.getenv("DB_USER")
|
||||
DB_PASSWORD = os.getenv("DB_PASSWORD")
|
||||
|
||||
|
||||
def save_user(user_id, email, password):
|
||||
try:
|
||||
@@ -90,6 +85,16 @@ def save_app(args):
|
||||
return app
|
||||
|
||||
|
||||
def save_user_app(user_id, app_id, workspace):
|
||||
try:
|
||||
user_app = UserApps.get((UserApps.user == user_id) & (UserApps.app == app_id))
|
||||
user_app.workspace = workspace
|
||||
user_app.save()
|
||||
except DoesNotExist:
|
||||
user_app = UserApps.create(user=user_id, app=app_id, workspace=workspace)
|
||||
|
||||
return user_app
|
||||
|
||||
def save_progress(app_id, step, data):
|
||||
progress_table_map = {
|
||||
'project_description': ProjectDescription,
|
||||
@@ -130,6 +135,14 @@ def get_app(app_id):
|
||||
raise ValueError(f"No app with id: {app_id}")
|
||||
|
||||
|
||||
def get_app_by_user_workspace(user_id, workspace):
|
||||
try:
|
||||
user_app = UserApps.get((UserApps.user == user_id) & (UserApps.workspace == workspace))
|
||||
return user_app.app
|
||||
except DoesNotExist:
|
||||
return None
|
||||
|
||||
|
||||
def get_progress_steps(app_id, step=None):
|
||||
progress_table_map = {
|
||||
'project_description': ProjectDescription,
|
||||
@@ -215,9 +228,13 @@ def save_development_step(project, prompt_path, prompt_data, messages, llm_respo
|
||||
'previous_step': project.checkpoints['last_development_step'],
|
||||
}
|
||||
|
||||
development_step = hash_and_save_step(DevelopmentSteps, project.args['app_id'], hash_data_args, data_fields,
|
||||
"Saved Development Step")
|
||||
development_step = hash_and_save_step(DevelopmentSteps, project.args['app_id'], hash_data_args, data_fields, "Saved Development Step")
|
||||
project.checkpoints['last_development_step'] = development_step
|
||||
|
||||
|
||||
project.save_files_snapshot(development_step.id)
|
||||
|
||||
|
||||
return development_step
|
||||
|
||||
|
||||
@@ -311,7 +328,7 @@ def get_all_connected_steps(step, previous_step_field_name):
|
||||
|
||||
|
||||
def delete_all_app_development_data(app):
|
||||
models = [DevelopmentSteps, CommandRuns, UserInputs, File, FileSnapshot]
|
||||
models = [DevelopmentSteps, CommandRuns, UserInputs, UserApps, File, FileSnapshot]
|
||||
for model in models:
|
||||
model.delete().where(model.app == app).execute()
|
||||
|
||||
@@ -356,6 +373,7 @@ def create_tables():
|
||||
Development,
|
||||
FileSnapshot,
|
||||
CommandRuns,
|
||||
UserApps,
|
||||
UserInputs,
|
||||
File,
|
||||
])
|
||||
@@ -376,10 +394,18 @@ def drop_tables():
|
||||
Development,
|
||||
FileSnapshot,
|
||||
CommandRuns,
|
||||
UserApps,
|
||||
UserInputs,
|
||||
File,
|
||||
]:
|
||||
database.execute_sql(f'DROP TABLE IF EXISTS "{table._meta.table_name}" CASCADE')
|
||||
if DATABASE_TYPE == "postgres":
|
||||
sql = f'DROP TABLE IF EXISTS "{table._meta.table_name}" CASCADE'
|
||||
elif DATABASE_TYPE == "sqlite":
|
||||
sql = f'DROP TABLE IF EXISTS "{table._meta.table_name}"'
|
||||
else:
|
||||
raise ValueError(f"Unsupported DATABASE_TYPE: {DATABASE_TYPE}")
|
||||
|
||||
database.execute_sql(sql)
|
||||
|
||||
|
||||
def database_exists():
|
||||
@@ -392,35 +418,42 @@ def database_exists():
|
||||
|
||||
|
||||
def create_database():
|
||||
# Connect to the default 'postgres' database to create a new database
|
||||
conn = psycopg2.connect(
|
||||
dbname='postgres',
|
||||
user=DB_USER,
|
||||
password=DB_PASSWORD,
|
||||
host=DB_HOST,
|
||||
port=DB_PORT
|
||||
)
|
||||
conn.autocommit = True
|
||||
cursor = conn.cursor()
|
||||
if DATABASE_TYPE == "postgres":
|
||||
# Connect to the default 'postgres' database to create a new database
|
||||
conn = psycopg2.connect(
|
||||
dbname='postgres',
|
||||
user=DB_USER,
|
||||
password=DB_PASSWORD,
|
||||
host=DB_HOST,
|
||||
port=DB_PORT
|
||||
)
|
||||
conn.autocommit = True
|
||||
cursor = conn.cursor()
|
||||
|
||||
# Safely quote the database name
|
||||
safe_db_name = quote_ident(DB_NAME, conn)
|
||||
# Safely quote the database name
|
||||
safe_db_name = quote_ident(DB_NAME, conn)
|
||||
|
||||
# Use the safely quoted database name in the SQL query
|
||||
cursor.execute(f"CREATE DATABASE {safe_db_name}")
|
||||
# Use the safely quoted database name in the SQL query
|
||||
cursor.execute(f"CREATE DATABASE {safe_db_name}")
|
||||
|
||||
cursor.close()
|
||||
conn.close()
|
||||
cursor.close()
|
||||
conn.close()
|
||||
else:
|
||||
pass
|
||||
|
||||
|
||||
def tables_exist():
|
||||
tables = [User, App, ProjectDescription, UserStories, UserTasks, Architecture, DevelopmentPlanning,
|
||||
DevelopmentSteps, EnvironmentSetup, Development, FileSnapshot, CommandRuns, UserInputs, File]
|
||||
for table in tables:
|
||||
try:
|
||||
database.get_tables().index(table._meta.table_name)
|
||||
except ValueError:
|
||||
return False
|
||||
DevelopmentSteps, EnvironmentSetup, Development, FileSnapshot, CommandRuns, UserApps, UserInputs, File]
|
||||
|
||||
if DATABASE_TYPE == "postgres":
|
||||
for table in tables:
|
||||
try:
|
||||
database.get_tables().index(table._meta.table_name)
|
||||
except ValueError:
|
||||
return False
|
||||
else:
|
||||
pass
|
||||
return True
|
||||
|
||||
|
||||
|
||||
@@ -1,10 +1,15 @@
|
||||
from peewee import *
|
||||
|
||||
from database.config import DATABASE_TYPE
|
||||
from database.models.components.progress_step import ProgressStep
|
||||
from database.models.components.sqlite_middlewares import JSONField
|
||||
from playhouse.postgres_ext import BinaryJSONField
|
||||
|
||||
|
||||
class Architecture(ProgressStep):
|
||||
architecture = BinaryJSONField()
|
||||
if DATABASE_TYPE == 'postgres':
|
||||
architecture = BinaryJSONField()
|
||||
else:
|
||||
architecture = JSONField() # Custom JSON field for SQLite
|
||||
|
||||
class Meta:
|
||||
db_table = 'architecture'
|
||||
table_name = 'architecture'
|
||||
|
||||
@@ -13,7 +13,7 @@ class CommandRuns(BaseModel):
|
||||
previous_step = ForeignKeyField('self', null=True, column_name='previous_step')
|
||||
|
||||
class Meta:
|
||||
db_table = 'command_runs'
|
||||
table_name = 'command_runs'
|
||||
indexes = (
|
||||
(('app', 'hash_id'), True),
|
||||
)
|
||||
@@ -1,23 +1,17 @@
|
||||
import os
|
||||
from peewee import *
|
||||
from datetime import datetime
|
||||
from uuid import uuid4
|
||||
|
||||
DB_NAME = os.getenv("DB_NAME")
|
||||
DB_HOST = os.getenv("DB_HOST")
|
||||
DB_PORT = os.getenv("DB_PORT")
|
||||
DB_USER = os.getenv("DB_USER")
|
||||
DB_PASSWORD = os.getenv("DB_PASSWORD")
|
||||
from database.config import DATABASE_TYPE
|
||||
from database.connection.postgres import get_postgres_database
|
||||
from database.connection.sqlite import get_sqlite_database
|
||||
|
||||
|
||||
# Establish connection to the database
|
||||
database = PostgresqlDatabase(
|
||||
DB_NAME,
|
||||
user=DB_USER,
|
||||
password=DB_PASSWORD,
|
||||
host=DB_HOST,
|
||||
port=DB_PORT
|
||||
)
|
||||
if DATABASE_TYPE == "postgres":
|
||||
database = get_postgres_database()
|
||||
else:
|
||||
database = get_sqlite_database()
|
||||
|
||||
|
||||
class BaseModel(Model):
|
||||
|
||||
@@ -1,16 +1,23 @@
|
||||
from peewee import *
|
||||
|
||||
from playhouse.postgres_ext import BinaryJSONField
|
||||
|
||||
from database.config import DATABASE_TYPE
|
||||
from database.models.components.base_models import BaseModel
|
||||
from database.models.app import App
|
||||
from database.models.components.sqlite_middlewares import JSONField
|
||||
from playhouse.postgres_ext import BinaryJSONField
|
||||
|
||||
|
||||
class ProgressStep(BaseModel):
|
||||
app = ForeignKeyField(App, primary_key=True, on_delete='CASCADE')
|
||||
step = CharField()
|
||||
data = BinaryJSONField(null=True)
|
||||
messages = BinaryJSONField(null=True)
|
||||
app_data = BinaryJSONField()
|
||||
|
||||
if DATABASE_TYPE == 'postgres':
|
||||
app_data = BinaryJSONField()
|
||||
data = BinaryJSONField(null=True)
|
||||
messages = BinaryJSONField(null=True)
|
||||
else:
|
||||
app_data = JSONField()
|
||||
data = JSONField(null=True)
|
||||
messages = JSONField(null=True)
|
||||
|
||||
completed = BooleanField(default=False)
|
||||
completed_at = DateTimeField(null=True)
|
||||
|
||||
14
pilot/database/models/components/sqlite_middlewares.py
Normal file
14
pilot/database/models/components/sqlite_middlewares.py
Normal file
@@ -0,0 +1,14 @@
|
||||
import json
|
||||
from peewee import TextField
|
||||
|
||||
|
||||
class JSONField(TextField):
|
||||
def python_value(self, value):
|
||||
if value is not None:
|
||||
return json.loads(value)
|
||||
return value
|
||||
|
||||
def db_value(self, value):
|
||||
if value is not None:
|
||||
return json.dumps(value)
|
||||
return value
|
||||
@@ -5,4 +5,4 @@ from database.models.components.progress_step import ProgressStep
|
||||
|
||||
class Development(ProgressStep):
|
||||
class Meta:
|
||||
db_table = 'development'
|
||||
table_name = 'development'
|
||||
|
||||
@@ -1,11 +1,15 @@
|
||||
from peewee import *
|
||||
|
||||
from database.config import DATABASE_TYPE
|
||||
from database.models.components.progress_step import ProgressStep
|
||||
from database.models.components.sqlite_middlewares import JSONField
|
||||
from playhouse.postgres_ext import BinaryJSONField
|
||||
|
||||
|
||||
class DevelopmentPlanning(ProgressStep):
|
||||
development_plan = BinaryJSONField()
|
||||
if DATABASE_TYPE == 'postgres':
|
||||
development_plan = BinaryJSONField()
|
||||
else:
|
||||
development_plan = JSONField() # Custom JSON field for SQLite
|
||||
|
||||
class Meta:
|
||||
db_table = 'development_planning'
|
||||
table_name = 'development_planning'
|
||||
|
||||
@@ -1,21 +1,26 @@
|
||||
from peewee import *
|
||||
|
||||
from playhouse.postgres_ext import BinaryJSONField
|
||||
|
||||
from database.config import DATABASE_TYPE
|
||||
from database.models.components.base_models import BaseModel
|
||||
from database.models.app import App
|
||||
|
||||
from database.models.components.sqlite_middlewares import JSONField
|
||||
from playhouse.postgres_ext import BinaryJSONField
|
||||
|
||||
class DevelopmentSteps(BaseModel):
|
||||
id = AutoField() # This will serve as the primary key
|
||||
app = ForeignKeyField(App, on_delete='CASCADE')
|
||||
hash_id = CharField(null=False)
|
||||
messages = BinaryJSONField(null=True)
|
||||
llm_response = BinaryJSONField(null=False)
|
||||
|
||||
if DATABASE_TYPE == 'postgres':
|
||||
messages = BinaryJSONField(null=True)
|
||||
llm_response = BinaryJSONField(null=False)
|
||||
else:
|
||||
messages = JSONField(null=True) # Custom JSON field for SQLite
|
||||
llm_response = JSONField(null=False) # Custom JSON field for SQLite
|
||||
|
||||
previous_step = ForeignKeyField('self', null=True, column_name='previous_step')
|
||||
|
||||
class Meta:
|
||||
db_table = 'development_steps'
|
||||
table_name = 'development_steps'
|
||||
indexes = (
|
||||
(('app', 'hash_id'), True),
|
||||
)
|
||||
)
|
||||
|
||||
@@ -3,4 +3,4 @@ from database.models.components.progress_step import ProgressStep
|
||||
|
||||
class EnvironmentSetup(ProgressStep):
|
||||
class Meta:
|
||||
db_table = 'environment_setup'
|
||||
table_name = 'environment_setup'
|
||||
|
||||
@@ -12,7 +12,7 @@ class FileSnapshot(BaseModel):
|
||||
content = TextField()
|
||||
|
||||
class Meta:
|
||||
db_table = 'file_snapshot'
|
||||
table_name = 'file_snapshot'
|
||||
indexes = (
|
||||
(('development_step', 'file'), True),
|
||||
)
|
||||
@@ -1,7 +1,4 @@
|
||||
from peewee import *
|
||||
|
||||
from playhouse.postgres_ext import BinaryJSONField
|
||||
|
||||
from database.models.components.progress_step import ProgressStep
|
||||
|
||||
|
||||
@@ -10,4 +7,4 @@ class ProjectDescription(ProgressStep):
|
||||
summary = TextField()
|
||||
|
||||
class Meta:
|
||||
db_table = 'project_description'
|
||||
table_name = 'project_description'
|
||||
|
||||
18
pilot/database/models/user_apps.py
Normal file
18
pilot/database/models/user_apps.py
Normal file
@@ -0,0 +1,18 @@
|
||||
from peewee import *
|
||||
|
||||
from database.models.components.base_models import BaseModel
|
||||
from database.models.app import App
|
||||
from database.models.user import User
|
||||
|
||||
|
||||
class UserApps(BaseModel):
|
||||
id = AutoField()
|
||||
app = ForeignKeyField(App, on_delete='CASCADE')
|
||||
user = ForeignKeyField(User, on_delete='CASCADE')
|
||||
workspace = CharField(null=True)
|
||||
|
||||
class Meta:
|
||||
table_name = 'user_apps'
|
||||
indexes = (
|
||||
(('app', 'user'), True),
|
||||
)
|
||||
@@ -13,7 +13,7 @@ class UserInputs(BaseModel):
|
||||
previous_step = ForeignKeyField('self', null=True, column_name='previous_step')
|
||||
|
||||
class Meta:
|
||||
db_table = 'user_inputs'
|
||||
table_name = 'user_inputs'
|
||||
indexes = (
|
||||
(('app', 'hash_id'), True),
|
||||
)
|
||||
@@ -1,10 +1,14 @@
|
||||
from peewee import *
|
||||
|
||||
from database.config import DATABASE_TYPE
|
||||
from database.models.components.progress_step import ProgressStep
|
||||
from database.models.components.sqlite_middlewares import JSONField
|
||||
from playhouse.postgres_ext import BinaryJSONField
|
||||
|
||||
|
||||
class UserStories(ProgressStep):
|
||||
user_stories = BinaryJSONField()
|
||||
if DATABASE_TYPE == 'postgres':
|
||||
user_stories = BinaryJSONField()
|
||||
else:
|
||||
user_stories = JSONField() # Custom JSON field for SQLite
|
||||
class Meta:
|
||||
db_table = 'user_stories'
|
||||
table_name = 'user_stories'
|
||||
|
||||
@@ -1,10 +1,15 @@
|
||||
from peewee import *
|
||||
|
||||
from database.config import DATABASE_TYPE
|
||||
from database.models.components.progress_step import ProgressStep
|
||||
from database.models.components.sqlite_middlewares import JSONField
|
||||
from playhouse.postgres_ext import BinaryJSONField
|
||||
|
||||
|
||||
class UserTasks(ProgressStep):
|
||||
user_tasks = BinaryJSONField()
|
||||
if DATABASE_TYPE == 'postgres':
|
||||
user_tasks = BinaryJSONField()
|
||||
else:
|
||||
user_tasks = JSONField() # Custom JSON field for SQLite
|
||||
|
||||
class Meta:
|
||||
db_table = 'user_tasks'
|
||||
table_name = 'user_tasks'
|
||||
|
||||
6
pilot/db_init.py
Normal file
6
pilot/db_init.py
Normal file
@@ -0,0 +1,6 @@
|
||||
from dotenv import load_dotenv
|
||||
load_dotenv()
|
||||
from database.database import create_tables, drop_tables
|
||||
|
||||
drop_tables()
|
||||
create_tables()
|
||||
@@ -11,6 +11,12 @@ from const.llm import END_RESPONSE
|
||||
|
||||
|
||||
class AgentConvo:
|
||||
"""
|
||||
Represents a conversation with an agent.
|
||||
|
||||
Args:
|
||||
agent: An instance of the agent participating in the conversation.
|
||||
"""
|
||||
def __init__(self, agent):
|
||||
self.messages = []
|
||||
self.branches = {}
|
||||
@@ -22,12 +28,20 @@ class AgentConvo:
|
||||
self.messages.append(get_sys_message(self.agent.role))
|
||||
|
||||
def send_message(self, prompt_path=None, prompt_data=None, function_calls=None):
|
||||
"""
|
||||
Sends a message in the conversation.
|
||||
|
||||
Args:
|
||||
prompt_path: The path to a prompt.
|
||||
prompt_data: Data associated with the prompt.
|
||||
function_calls: Optional function calls to be included in the message.
|
||||
|
||||
Returns:
|
||||
The response from the agent.
|
||||
"""
|
||||
# craft message
|
||||
self.construct_and_add_message_from_prompt(prompt_path, prompt_data)
|
||||
|
||||
if function_calls is not None and 'function_calls' in function_calls:
|
||||
self.messages[-1]['content'] += '\nMAKE SURE THAT YOU RESPOND WITH A CORRECT JSON FORMAT!!!'
|
||||
|
||||
# check if we already have the LLM response saved
|
||||
if self.agent.__class__.__name__ == 'Developer':
|
||||
self.agent.project.llm_req_num += 1
|
||||
@@ -52,7 +66,6 @@ class AgentConvo:
|
||||
if self.agent.__class__.__name__ == 'Developer':
|
||||
development_step = save_development_step(self.agent.project, prompt_path, prompt_data, self.messages, response)
|
||||
self.agent.project.checkpoints['last_development_step'] = development_step
|
||||
self.agent.project.save_files_snapshot(development_step.id)
|
||||
|
||||
# TODO handle errors from OpenAI
|
||||
if response == {}:
|
||||
@@ -84,6 +97,17 @@ class AgentConvo:
|
||||
return response
|
||||
|
||||
def continuous_conversation(self, prompt_path, prompt_data, function_calls=None):
|
||||
"""
|
||||
Conducts a continuous conversation with the agent.
|
||||
|
||||
Args:
|
||||
prompt_path: The path to a prompt.
|
||||
prompt_data: Data associated with the prompt.
|
||||
function_calls: Optional function calls to be included in the conversation.
|
||||
|
||||
Returns:
|
||||
List of accepted messages in the conversation.
|
||||
"""
|
||||
self.log_to_user = False
|
||||
accepted_messages = []
|
||||
response = self.send_message(prompt_path, prompt_data, function_calls)
|
||||
@@ -112,6 +136,16 @@ class AgentConvo:
|
||||
return len([msg for msg in self.messages if msg['role'] != 'system'])
|
||||
|
||||
def postprocess_response(self, response, function_calls):
|
||||
"""
|
||||
Post-processes the response from the agent.
|
||||
|
||||
Args:
|
||||
response: The response from the agent.
|
||||
function_calls: Optional function calls associated with the response.
|
||||
|
||||
Returns:
|
||||
The post-processed response.
|
||||
"""
|
||||
if 'function_calls' in response and function_calls is not None:
|
||||
if 'send_convo' in function_calls:
|
||||
response['function_calls']['arguments']['convo'] = self
|
||||
@@ -122,9 +156,17 @@ class AgentConvo:
|
||||
return response
|
||||
|
||||
def log_message(self, content):
|
||||
"""
|
||||
Logs a message in the conversation.
|
||||
|
||||
Args:
|
||||
content: The content of the message to be logged.
|
||||
"""
|
||||
print_msg = capitalize_first_word_with_underscores(self.high_level_step)
|
||||
if self.log_to_user:
|
||||
print(colored("Dev step ", 'yellow') + colored(self.agent.project.checkpoints['last_development_step'], 'yellow', attrs=['bold']) + f"\n{content}\n")
|
||||
if self.agent.project.checkpoints['last_development_step'] is not None:
|
||||
print(colored("\nDev step ", 'yellow') + colored(self.agent.project.checkpoints['last_development_step'], 'yellow', attrs=['bold']) + '\n', end='')
|
||||
print(f"\n{content}\n")
|
||||
logger.info(f"{print_msg}: {content}\n")
|
||||
|
||||
def to_playground(self):
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
import os
|
||||
|
||||
from termcolor import colored
|
||||
from const.common import IGNORE_FOLDERS
|
||||
from const.common import IGNORE_FOLDERS, STEPS
|
||||
from database.models.app import App
|
||||
from database.database import get_app, delete_unconnected_steps_from, delete_all_app_development_data
|
||||
from utils.questionary import styled_text
|
||||
@@ -21,6 +21,19 @@ from utils.files import get_parent_folder
|
||||
class Project:
|
||||
def __init__(self, args, name=None, description=None, user_stories=None, user_tasks=None, architecture=None,
|
||||
development_plan=None, current_step=None):
|
||||
"""
|
||||
Initialize a project.
|
||||
|
||||
Args:
|
||||
args (dict): Project arguments - app_id, (app_type, name), user_id, email, password, step
|
||||
name (str, optional): Project name. Default is None.
|
||||
description (str, optional): Project description. Default is None.
|
||||
user_stories (list, optional): List of user stories. Default is None.
|
||||
user_tasks (list, optional): List of user tasks. Default is None.
|
||||
architecture (str, optional): Project architecture. Default is None.
|
||||
development_plan (str, optional): Development plan. Default is None.
|
||||
current_step (str, optional): Current step in the project. Default is None.
|
||||
"""
|
||||
self.args = args
|
||||
self.llm_req_num = 0
|
||||
self.command_runs_count = 0
|
||||
@@ -52,6 +65,9 @@ class Project:
|
||||
# self.development_plan = development_plan
|
||||
|
||||
def start(self):
|
||||
"""
|
||||
Start the project.
|
||||
"""
|
||||
self.project_manager = ProductOwner(self)
|
||||
self.project_manager.get_project_description()
|
||||
self.user_stories = self.project_manager.get_user_stories()
|
||||
@@ -64,6 +80,11 @@ class Project:
|
||||
# self.development_plan = self.tech_lead.create_development_plan()
|
||||
|
||||
# TODO move to constructor eventually
|
||||
if self.args['step'] is not None and STEPS.index(self.args['step']) < STEPS.index('coding'):
|
||||
clear_directory(self.root_path)
|
||||
delete_all_app_development_data(self.args['app_id'])
|
||||
self.skip_steps = False
|
||||
|
||||
if 'skip_until_dev_step' in self.args:
|
||||
self.skip_until_dev_step = self.args['skip_until_dev_step']
|
||||
if self.args['skip_until_dev_step'] == '0':
|
||||
@@ -76,11 +97,20 @@ class Project:
|
||||
# TODO END
|
||||
|
||||
self.developer = Developer(self)
|
||||
self.developer.set_up_environment();
|
||||
self.developer.set_up_environment()
|
||||
|
||||
self.developer.start_coding()
|
||||
|
||||
def get_directory_tree(self, with_descriptions=False):
|
||||
"""
|
||||
Get the directory tree of the project.
|
||||
|
||||
Args:
|
||||
with_descriptions (bool, optional): Whether to include descriptions. Default is False.
|
||||
|
||||
Returns:
|
||||
dict: The directory tree.
|
||||
"""
|
||||
files = {}
|
||||
if with_descriptions and False:
|
||||
files = File.select().where(File.app_id == self.args['app_id'])
|
||||
@@ -88,15 +118,36 @@ class Project:
|
||||
return build_directory_tree(self.root_path + '/', ignore=IGNORE_FOLDERS, files=files, add_descriptions=False)
|
||||
|
||||
def get_test_directory_tree(self):
|
||||
"""
|
||||
Get the directory tree of the tests.
|
||||
|
||||
Returns:
|
||||
dict: The directory tree of tests.
|
||||
"""
|
||||
# TODO remove hardcoded path
|
||||
return build_directory_tree(self.root_path + '/tests', ignore=IGNORE_FOLDERS)
|
||||
|
||||
def get_all_coded_files(self):
|
||||
"""
|
||||
Get all coded files in the project.
|
||||
|
||||
Returns:
|
||||
list: A list of coded files.
|
||||
"""
|
||||
files = File.select().where(File.app_id == self.args['app_id'])
|
||||
files = self.get_files([file.path + '/' + file.name for file in files])
|
||||
return files
|
||||
|
||||
def get_files(self, files):
|
||||
"""
|
||||
Get file contents.
|
||||
|
||||
Args:
|
||||
files (list): List of file paths.
|
||||
|
||||
Returns:
|
||||
list: A list of files with content.
|
||||
"""
|
||||
files_with_content = []
|
||||
for file in files:
|
||||
# TODO this is a hack, fix it
|
||||
@@ -113,6 +164,12 @@ class Project:
|
||||
return files_with_content
|
||||
|
||||
def save_file(self, data):
|
||||
"""
|
||||
Save a file.
|
||||
|
||||
Args:
|
||||
data (dict): File data.
|
||||
"""
|
||||
# TODO fix this in prompts
|
||||
if ' ' in data['name'] or '.' not in data['name']:
|
||||
data['name'] = data['path'].rsplit('/', 1)[1]
|
||||
@@ -150,6 +207,7 @@ class Project:
|
||||
development_step, created = DevelopmentSteps.get_or_create(id=development_step_id)
|
||||
|
||||
for file in files:
|
||||
print(colored(f'Saving file {file["path"] + "/" + file["name"]}', 'light_cyan'))
|
||||
# TODO this can be optimized so we don't go to the db each time
|
||||
file_in_db, created = File.get_or_create(
|
||||
app=self.app,
|
||||
@@ -181,14 +239,14 @@ class Project:
|
||||
delete_unconnected_steps_from(self.checkpoints['last_user_input'], 'previous_step')
|
||||
|
||||
def ask_for_human_intervention(self, message, description=None, cbs={}):
|
||||
print(colored(message, "yellow"))
|
||||
print(colored(message, "yellow", attrs=['bold']))
|
||||
if description is not None:
|
||||
print(description)
|
||||
answer = ''
|
||||
while answer != 'continue':
|
||||
answer = styled_text(
|
||||
self,
|
||||
'Once you are ready, type "continue" to continue.',
|
||||
'If something is wrong, tell me or type "continue" to continue.',
|
||||
)
|
||||
|
||||
if answer in cbs:
|
||||
|
||||
@@ -29,7 +29,7 @@ class CodeMonkey(Agent):
|
||||
}, IMPLEMENT_CHANGES)
|
||||
convo.remove_last_x_messages(1)
|
||||
|
||||
if (not self.project.args['update_files_before_start']) or (self.project.skip_until_dev_step != str(self.project.checkpoints['last_development_step'].id)):
|
||||
if ('update_files_before_start' not in self.project.args) or (self.project.skip_until_dev_step != str(self.project.checkpoints['last_development_step'].id)):
|
||||
for file_data in changes:
|
||||
self.project.save_file(file_data)
|
||||
|
||||
|
||||
@@ -18,6 +18,7 @@ from helpers.cli import execute_command
|
||||
class Developer(Agent):
|
||||
def __init__(self, project):
|
||||
super().__init__('full_stack_developer', project)
|
||||
self.run_command = None
|
||||
|
||||
def start_coding(self):
|
||||
self.project.current_step = 'coding'
|
||||
@@ -26,7 +27,7 @@ class Developer(Agent):
|
||||
self.project.skip_steps = False if ('skip_until_dev_step' in self.project.args and self.project.args['skip_until_dev_step'] == '0') else True
|
||||
|
||||
# DEVELOPMENT
|
||||
print(colored(f"Ok, great, now, let's start with the actual development...\n", "green"))
|
||||
print(colored(f"Ok, great, now, let's start with the actual development...\n", "green", attrs=['bold']))
|
||||
logger.info(f"Starting to create the actual code...")
|
||||
|
||||
self.implement_task()
|
||||
@@ -39,6 +40,7 @@ class Developer(Agent):
|
||||
convo_dev_task = AgentConvo(self)
|
||||
task_description = convo_dev_task.send_message('development/task/breakdown.prompt', {
|
||||
"name": self.project.args['name'],
|
||||
"app_type": self.project.args['app_type'],
|
||||
"app_summary": self.project.project_description,
|
||||
"clarification": [],
|
||||
"user_stories": self.project.user_stories,
|
||||
@@ -88,7 +90,11 @@ class Developer(Agent):
|
||||
# TODO end
|
||||
|
||||
elif step['type'] == 'human_intervention':
|
||||
user_feedback = self.project.ask_for_human_intervention('I need your help! Can you try debugging this yourself and let me take over afterwards? Here are the details about the issue:', step['human_intervention_description'])
|
||||
human_intervention_description = step['human_intervention_description'] + colored('\n\nIf you want to run the app, just type "r" and press ENTER and that will run `' + self.run_command + '`', 'yellow', attrs=['bold']) if self.run_command is not None else step['human_intervention_description']
|
||||
user_feedback = self.project.ask_for_human_intervention('I need human intervention:',
|
||||
human_intervention_description,
|
||||
cbs={ 'r': lambda: run_command_until_success(self.run_command, None, convo, force=True) })
|
||||
|
||||
if user_feedback is not None and user_feedback != 'continue':
|
||||
debug(convo, user_input=user_feedback, issue_description=step['human_intervention_description'])
|
||||
|
||||
@@ -129,6 +135,7 @@ class Developer(Agent):
|
||||
iteration_convo = AgentConvo(self)
|
||||
iteration_convo.send_message('development/iteration.prompt', {
|
||||
"name": self.project.args['name'],
|
||||
"app_type": self.project.args['app_type'],
|
||||
"app_summary": self.project.project_description,
|
||||
"clarification": [],
|
||||
"user_stories": self.project.user_stories,
|
||||
@@ -170,7 +177,12 @@ class Developer(Agent):
|
||||
|
||||
os_info = get_os_info()
|
||||
os_specific_techologies = self.convo_os_specific_tech.send_message('development/env_setup/specs.prompt',
|
||||
{ "name": self.project.args['name'], "os_info": os_info, "technologies": self.project.architecture }, FILTER_OS_TECHNOLOGIES)
|
||||
{
|
||||
"name": self.project.args['name'],
|
||||
"app_type": self.project.args['app_type'],
|
||||
"os_info": os_info,
|
||||
"technologies": self.project.architecture
|
||||
}, FILTER_OS_TECHNOLOGIES)
|
||||
|
||||
for technology in os_specific_techologies:
|
||||
# TODO move the functions definisions to function_calls.py
|
||||
@@ -243,11 +255,11 @@ class Developer(Agent):
|
||||
'step_type': type,
|
||||
'directory_tree': directory_tree,
|
||||
'step_index': step_index
|
||||
}, EXECUTE_COMMANDS);
|
||||
}, EXECUTE_COMMANDS)
|
||||
if type == 'COMMAND':
|
||||
for cmd in step_details:
|
||||
run_command_until_success(cmd['command'], cmd['timeout'], convo)
|
||||
elif type == 'CODE_CHANGE':
|
||||
code_changes_details = get_step_code_changes()
|
||||
# elif type == 'CODE_CHANGE':
|
||||
# code_changes_details = get_step_code_changes()
|
||||
# TODO: give to code monkey for implementation
|
||||
pass
|
||||
|
||||
@@ -24,16 +24,17 @@ class ProductOwner(Agent):
|
||||
step = get_progress_steps(self.project.args['app_id'], self.project.current_step)
|
||||
if step and not execute_step(self.project.args['step'], self.project.current_step):
|
||||
step_already_finished(self.project.args, step)
|
||||
self.project.root_path = setup_workspace(self.project.args['name'])
|
||||
self.project.root_path = setup_workspace(self.project.args)
|
||||
self.project.project_description = step['summary']
|
||||
self.project.project_description_messages = step['messages']
|
||||
return
|
||||
|
||||
# PROJECT DESCRIPTION
|
||||
self.project.args['app_type'] = ask_for_app_type()
|
||||
self.project.args['name'] = clean_filename(ask_user(self.project, 'What is the project name?'))
|
||||
if 'name' not in self.project.args:
|
||||
self.project.args['name'] = clean_filename(ask_user(self.project, 'What is the project name?'))
|
||||
|
||||
self.project.root_path = setup_workspace(self.project.args['name'])
|
||||
self.project.root_path = setup_workspace(self.project.args)
|
||||
|
||||
self.project.app = save_app(self.project.args)
|
||||
|
||||
@@ -43,8 +44,11 @@ class ProductOwner(Agent):
|
||||
self.project,
|
||||
generate_messages_from_description(main_prompt, self.project.args['app_type'], self.project.args['name']))
|
||||
|
||||
print(colored('Project Summary:\n', 'green', attrs=['bold']))
|
||||
high_level_summary = convo_project_description.send_message('utils/summary.prompt',
|
||||
{'conversation': '\n'.join([f"{msg['role']}: {msg['content']}" for msg in high_level_messages])})
|
||||
{'conversation': '\n'.join(
|
||||
[f"{msg['role']}: {msg['content']}" for msg in
|
||||
high_level_messages])})
|
||||
|
||||
save_progress(self.project.args['app_id'], self.project.current_step, {
|
||||
"prompt": main_prompt,
|
||||
@@ -58,7 +62,6 @@ class ProductOwner(Agent):
|
||||
return
|
||||
# PROJECT DESCRIPTION END
|
||||
|
||||
|
||||
def get_user_stories(self):
|
||||
self.project.current_step = 'user_stories'
|
||||
self.convo_user_stories = AgentConvo(self)
|
||||
@@ -71,7 +74,7 @@ class ProductOwner(Agent):
|
||||
return step['user_stories']
|
||||
|
||||
# USER STORIES
|
||||
msg = f"Generating USER STORIES...\n"
|
||||
msg = f"User Stories:\n"
|
||||
print(colored(msg, "green", attrs=['bold']))
|
||||
logger.info(msg)
|
||||
|
||||
@@ -105,12 +108,12 @@ class ProductOwner(Agent):
|
||||
return step['user_tasks']
|
||||
|
||||
# USER TASKS
|
||||
msg = f"Generating USER TASKS...\n"
|
||||
msg = f"User Tasks:\n"
|
||||
print(colored(msg, "green", attrs=['bold']))
|
||||
logger.info(msg)
|
||||
|
||||
self.project.user_tasks = self.convo_user_stories.continuous_conversation('user_stories/user_tasks.prompt',
|
||||
{ 'END_RESPONSE': END_RESPONSE })
|
||||
{'END_RESPONSE': END_RESPONSE})
|
||||
|
||||
logger.info(f"Final user tasks: {self.project.user_tasks}")
|
||||
|
||||
|
||||
@@ -36,6 +36,7 @@ class TechLead(Agent):
|
||||
self.development_plan = self.convo_development_plan.send_message('development/plan.prompt',
|
||||
{
|
||||
"name": self.project.args['name'],
|
||||
"app_type": self.project.args['app_type'],
|
||||
"app_summary": self.project.project_description,
|
||||
"clarification": [],
|
||||
"user_stories": self.project.user_stories,
|
||||
|
||||
@@ -5,6 +5,7 @@ import threading
|
||||
import queue
|
||||
import time
|
||||
import uuid
|
||||
import platform
|
||||
|
||||
from termcolor import colored
|
||||
from database.database import get_command_run_from_hash_id, save_command_run
|
||||
@@ -23,15 +24,39 @@ def enqueue_output(out, q):
|
||||
out.close()
|
||||
|
||||
def run_command(command, root_path, q_stdout, q_stderr, pid_container):
|
||||
process = subprocess.Popen(
|
||||
command,
|
||||
shell=True,
|
||||
stdout=subprocess.PIPE,
|
||||
stderr=subprocess.PIPE,
|
||||
text=True,
|
||||
preexec_fn=os.setsid,
|
||||
cwd=root_path
|
||||
)
|
||||
"""
|
||||
Execute a command in a subprocess.
|
||||
|
||||
Args:
|
||||
command (str): The command to run.
|
||||
root_path (str): The directory in which to run the command.
|
||||
q_stdout (Queue): A queue to capture stdout.
|
||||
q_stderr (Queue): A queue to capture stderr.
|
||||
pid_container (list): A list to store the process ID.
|
||||
|
||||
Returns:
|
||||
subprocess.Popen: The subprocess object.
|
||||
"""
|
||||
if platform.system() == 'Windows': # Check the operating system
|
||||
process = subprocess.Popen(
|
||||
command,
|
||||
shell=True,
|
||||
stdout=subprocess.PIPE,
|
||||
stderr=subprocess.PIPE,
|
||||
text=True,
|
||||
cwd=root_path
|
||||
)
|
||||
else:
|
||||
process = subprocess.Popen(
|
||||
command,
|
||||
shell=True,
|
||||
stdout=subprocess.PIPE,
|
||||
stderr=subprocess.PIPE,
|
||||
text=True,
|
||||
preexec_fn=os.setsid, # Use os.setsid only for Unix-like systems
|
||||
cwd=root_path
|
||||
)
|
||||
|
||||
pid_container[0] = process.pid
|
||||
t_stdout = threading.Thread(target=enqueue_output, args=(process.stdout, q_stdout))
|
||||
t_stderr = threading.Thread(target=enqueue_output, args=(process.stderr, q_stderr))
|
||||
@@ -41,21 +66,53 @@ def run_command(command, root_path, q_stdout, q_stderr, pid_container):
|
||||
t_stderr.start()
|
||||
return process
|
||||
|
||||
def terminate_process(pid):
|
||||
if platform.system() == "Windows":
|
||||
try:
|
||||
subprocess.run(["taskkill", "/F", "/T", "/PID", str(pid)])
|
||||
except subprocess.CalledProcessError:
|
||||
# Handle any potential errors here
|
||||
pass
|
||||
else: # Unix-like systems
|
||||
try:
|
||||
os.killpg(pid, signal.SIGKILL)
|
||||
except OSError:
|
||||
# Handle any potential errors here
|
||||
pass
|
||||
|
||||
def execute_command(project, command, timeout=None, force=False):
|
||||
"""
|
||||
Execute a command and capture its output.
|
||||
|
||||
Args:
|
||||
project: The project associated with the command.
|
||||
command (str): The command to run.
|
||||
timeout (int, optional): The maximum execution time in milliseconds. Default is None.
|
||||
force (bool, optional): Whether to execute the command without confirmation. Default is False.
|
||||
|
||||
Returns:
|
||||
str: The command output.
|
||||
"""
|
||||
if timeout is not None:
|
||||
if timeout < 1000:
|
||||
timeout *= 1000
|
||||
timeout = min(max(timeout, MIN_COMMAND_RUN_TIME), MAX_COMMAND_RUN_TIME)
|
||||
|
||||
if not force:
|
||||
print(colored(f'Can i execute the command: `') + colored(command, 'white', attrs=['bold']) + colored(f'` with {timeout}ms timeout?'))
|
||||
print(colored(f'\n--------- EXECUTE COMMAND ----------', 'yellow', attrs=['bold']))
|
||||
print(colored(f'Can i execute the command: `') + colored(command, 'yellow', attrs=['bold']) + colored(f'` with {timeout}ms timeout?'))
|
||||
|
||||
answer = styled_text(
|
||||
project,
|
||||
'If yes, just press ENTER'
|
||||
)
|
||||
|
||||
|
||||
# TODO when a shell built-in commands (like cd or source) is executed, the output is not captured properly - this will need to be changed at some point
|
||||
if "cd " in command or "source " in command:
|
||||
command = "bash -c '" + command + "'"
|
||||
|
||||
|
||||
project.command_runs_count += 1
|
||||
command_run = get_command_run_from_hash_id(project, command)
|
||||
if command_run is not None and project.skip_steps:
|
||||
@@ -124,7 +181,7 @@ def execute_command(project, command, timeout=None, force=False):
|
||||
else:
|
||||
print("\nTimeout detected. Stopping command execution...")
|
||||
|
||||
os.killpg(pid_container[0], signal.SIGKILL) # Kill the process group
|
||||
terminate_process(pid_container[0])
|
||||
|
||||
# stderr_output = ''
|
||||
# while not q_stderr.empty():
|
||||
@@ -178,12 +235,33 @@ def build_directory_tree(path, prefix="", ignore=None, is_last=False, files=None
|
||||
return output
|
||||
|
||||
def execute_command_and_check_cli_response(command, timeout, convo):
|
||||
"""
|
||||
Execute a command and check its CLI response.
|
||||
|
||||
Args:
|
||||
command (str): The command to run.
|
||||
timeout (int): The maximum execution time in milliseconds.
|
||||
convo (AgentConvo): The conversation object.
|
||||
|
||||
Returns:
|
||||
tuple: A tuple containing the CLI response and the agent's response.
|
||||
"""
|
||||
cli_response = execute_command(convo.agent.project, command, timeout)
|
||||
response = convo.send_message('dev_ops/ran_command.prompt',
|
||||
{ 'cli_response': cli_response, 'command': command })
|
||||
return cli_response, response
|
||||
|
||||
def run_command_until_success(command, timeout, convo, additional_message=None, force=False):
|
||||
"""
|
||||
Run a command until it succeeds or reaches a timeout.
|
||||
|
||||
Args:
|
||||
command (str): The command to run.
|
||||
timeout (int): The maximum execution time in milliseconds.
|
||||
convo (AgentConvo): The conversation object.
|
||||
additional_message (str, optional): Additional message to include in the response.
|
||||
force (bool, optional): Whether to execute the command without confirmation. Default is False.
|
||||
"""
|
||||
cli_response = execute_command(convo.agent.project, command, timeout, force)
|
||||
response = convo.send_message('dev_ops/ran_command.prompt',
|
||||
{'cli_response': cli_response, 'command': command, 'additional_message': additional_message})
|
||||
@@ -198,6 +276,18 @@ def run_command_until_success(command, timeout, convo, additional_message=None,
|
||||
|
||||
|
||||
def debug(convo, command=None, user_input=None, issue_description=None):
|
||||
"""
|
||||
Debug a conversation.
|
||||
|
||||
Args:
|
||||
convo (AgentConvo): The conversation object.
|
||||
command (dict, optional): The command to debug. Default is None.
|
||||
user_input (str, optional): User input for debugging. Default is None.
|
||||
issue_description (str, optional): Description of the issue to debug. Default is None.
|
||||
|
||||
Returns:
|
||||
bool: True if debugging was successful, False otherwise.
|
||||
"""
|
||||
function_uuid = str(uuid.uuid4())
|
||||
convo.save_branch(function_uuid)
|
||||
success = False
|
||||
|
||||
0
pilot/logger/__init__.py
Normal file
0
pilot/logger/__init__.py
Normal file
@@ -1,12 +1,13 @@
|
||||
# main.py
|
||||
from __future__ import print_function, unicode_literals
|
||||
|
||||
import sys
|
||||
from dotenv import load_dotenv
|
||||
load_dotenv()
|
||||
|
||||
from termcolor import colored
|
||||
from helpers.Project import Project
|
||||
|
||||
from utils.arguments import get_arguments
|
||||
from utils.exit import exit_gpt_pilot
|
||||
from logger.logger import logger
|
||||
from database.database import database_exists, create_database, tables_exist, create_tables
|
||||
|
||||
@@ -28,8 +29,16 @@ def init():
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = init()
|
||||
|
||||
# TODO get checkpoint from database and fill the project with it
|
||||
project = Project(args)
|
||||
project.start()
|
||||
try:
|
||||
args = init()
|
||||
project = Project(args)
|
||||
project.start()
|
||||
except KeyboardInterrupt:
|
||||
exit_gpt_pilot()
|
||||
except Exception as e:
|
||||
print(colored('---------- GPT PILOT EXITING WITH ERROR ----------', 'red'))
|
||||
print(colored(e, 'red'))
|
||||
print(colored('--------------------------------------------------', 'red'))
|
||||
exit_gpt_pilot()
|
||||
finally:
|
||||
sys.exit(0)
|
||||
|
||||
@@ -29,4 +29,6 @@ Here are user tasks that specify what users need to do to interact with "{{ name
|
||||
|
||||
Now, based on the app's description, user stories and user tasks, think step by step and write up all technologies that will be used by your development team to create the app "{{ name }}". Do not write any explanations behind your choices but only a list of technologies that will be used.
|
||||
|
||||
You do not need to list any technologies related to automated tests like Jest, Cypress, Mocha, Selenium, etc.
|
||||
You do not need to list any technologies related to automated tests like Jest, Cypress, Mocha, Selenium, etc.
|
||||
|
||||
{{no_microservices}}
|
||||
|
||||
2
pilot/prompts/components/no_microservices.prompt
Normal file
2
pilot/prompts/components/no_microservices.prompt
Normal file
@@ -0,0 +1,2 @@
|
||||
**IMPORTANT**
|
||||
Do not use, create or suggest any microservices. Create strictly monolithic application even if in some prompts I might suggest microservices might be better or more desired solution. Do your best to find a solution to any requirement without using microservices.
|
||||
@@ -7,7 +7,7 @@ You wanted me to check this - `{{ issue_description }}` but there was a problem{
|
||||
|
||||
`run_command` function will run a command on the machine and will return the CLI output to you so you can see what to do next.
|
||||
|
||||
`implement_code_changes` function will change the code where you just need to thoroughly describe what needs to be implmemented, I will implement the requested changes and let you know.
|
||||
`implement_code_changes` function will change the code where you just need to thoroughly describe what needs to be implemented, I will implement the requested changes and let you know.
|
||||
|
||||
Return a list of steps that are needed to debug this issue. By the time we execute the last step, the issue should be fixed completely. Also, make sure that at least the last step has `check_if_fixed` set to TRUE.
|
||||
|
||||
|
||||
@@ -1,4 +1,2 @@
|
||||
Response from the CLI:
|
||||
```
|
||||
{{ cli_response }}
|
||||
```
|
||||
{{ cli_response }}
|
||||
@@ -1,4 +1,4 @@
|
||||
You are working in a software development agency and a project manager and software architect approach you telling you that you're assigned to work on a new project. You are working on a web app called "{{ name }}" and your first job is to set up the environment on a computer.
|
||||
You are working in a software development agency and a project manager and software architect approach you telling you that you're assigned to work on a new project. You are working on a {{ app_type }} called "{{ name }}" and your first job is to set up the environment on a computer.
|
||||
|
||||
Here are the technologies that you need to use for this project:
|
||||
```
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
How can I run this app?
|
||||
!IMPORTANT!
|
||||
**IMPORTANT**
|
||||
Do not reply with anything else but the command with which I can run this app with.
|
||||
For example, if the command is "python app.py", then your response needs to be only `python app.py` without the `
|
||||
@@ -1,14 +1,10 @@
|
||||
{% if files|length > 0 %}
|
||||
Here is how files look now:
|
||||
{% if files|length > 0 %}Here is how files look now:
|
||||
{% for file in files %}
|
||||
**{{ file.path }}**
|
||||
```{# file.language #}
|
||||
{{ file.content }}
|
||||
```
|
||||
|
||||
{% endfor %}
|
||||
{% endif %}
|
||||
|
||||
Now, think step by step and apply the needed changes for step #{{ step_index }} - {{ step_description }}.
|
||||
{% endfor %}{% endif %}Now, think step by step and apply the needed changes for step #{{ step_index }} - `{{ step_description }}`.
|
||||
|
||||
Within the file modifications, anything needs to be written by the user, add the comment in the same line as the code that starts with `// INPUT_REQUIRED {input_description}` where `input_description` is a description of what needs to be added here by the user. Finally, you can save the modified files on the disk by calling `save_files` function.
|
||||
@@ -1,4 +1,4 @@
|
||||
You are working on a web app called "{{ name }}" and you need to write code for the entire application.
|
||||
You are working on a {{ app_type }} called "{{ name }}" and you need to write code for the entire application.
|
||||
|
||||
Here is a high level description of "{{ name }}":
|
||||
```
|
||||
@@ -31,5 +31,5 @@ Tell me all the new code that needs to be written or modified to implement this
|
||||
#}
|
||||
Remember, I'm currently in an empty folder where I will start writing files that you tell me. You do not need to make any automated tests work.
|
||||
|
||||
!!IMPORTANT!!
|
||||
**IMPORTANT**
|
||||
Do not tell me anything about setting up the database or anything OS related - only if some dependencies need to be installed.
|
||||
@@ -1,4 +1,4 @@
|
||||
You are working in a software development agency and a project manager and software architect approach you telling you that you're assigned to work on a new project. You are working on a web app called "{{ name }}" and you need to create a detailed development plan so that developers can start developing the app.
|
||||
You are working in a software development agency and a project manager and software architect approach you telling you that you're assigned to work on a new project. You are working on a {{ app_type }} called "{{ name }}" and you need to create a detailed development plan so that developers can start developing the app.
|
||||
|
||||
Here is a high level description of "{{ name }}":
|
||||
```
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
You are working on a web app called "{{ name }}" and you need to write code for the entire application based on the tasks that the tech lead gives you. So that you understand better what you're working on, you're given other specs for "{{ name }}" as well.
|
||||
You are working on a {{ app_type }} called "{{ name }}" and you need to write code for the entire application based on the tasks that the tech lead gives you. So that you understand better what you're working on, you're given other specs for "{{ name }}" as well.
|
||||
|
||||
Here is a high level description of "{{ name }}":
|
||||
```
|
||||
@@ -20,22 +20,24 @@ Here are the technologies that you need to use for this project:
|
||||
- {{ tech }}{% endfor %}
|
||||
```
|
||||
|
||||
{% if parent_task %}
|
||||
You are currently working on this task:
|
||||
```
|
||||
{{ array_of_objects_to_string(parent_task) }}
|
||||
```
|
||||
We've broken it down to these subtasks:
|
||||
```{% for subtask in sibling_tasks %}
|
||||
- {{ subtask['description'] }}{% endfor %}
|
||||
{% if current_task_index != 0 %}
|
||||
So far, this code has been implemented
|
||||
{% for file in files %}
|
||||
**{{ file.path }}**
|
||||
```{# file.language #}
|
||||
{{ file.content }}
|
||||
```
|
||||
|
||||
{% endfor %}
|
||||
{% endif %}
|
||||
|
||||
Now, tell me all the code that needs to be written to implement this app and have it fully working and all commands that need to be run to implement this app.
|
||||
|
||||
This should be a simple version of the app so you don't need to aim to provide a production ready code but rather something that a developer can run locally and play with the implementation. Do not leave any parts of the code to be written afterwards. Make sure that all the code you provide is working and does as outlined in the description area above.
|
||||
|
||||
!IMPORTANT!
|
||||
{{no_microservices}}
|
||||
|
||||
**IMPORTANT**
|
||||
Remember, I'm currently in an empty folder where I will start writing files that you tell me.
|
||||
Tell me how can I test the app to see if it's working or not.
|
||||
You do not need to make any automated tests work.
|
||||
|
||||
@@ -1,13 +1,8 @@
|
||||
{#You need to implement the current changes into a codebase:
|
||||
-- INSTRUCTIONS --
|
||||
{{ instructions }}
|
||||
-- END OF INSTRUCTIONS --#}
|
||||
{% if step_index != 0 %}
|
||||
So far, steps {{ finished_steps }} are finished so let's do
|
||||
{% else %}
|
||||
Let's start with the
|
||||
{% endif %}
|
||||
step #{{ step_index }} - `{{ step_description }}`.
|
||||
-- END OF INSTRUCTIONS --
|
||||
#}{% if step_index != 0 %}So far, steps {{ finished_steps }} are finished so let's do{% else %}Let's start with the{% endif %} step #{{ step_index }} - `{{ step_description }}`.
|
||||
|
||||
{# I will give you each file that needs to be changed and you will implement changes from the instructions. #}To do this, you will need to see the currently implemented files so first, filter the files outlined above that are relevant for the instructions. Then, tell me files that you need to see so that you can make appropriate changes to the code. If no files are needed (eg. if you need to create a file), just return an empty array.
|
||||
{#
|
||||
|
||||
@@ -21,4 +21,6 @@ Here is an overview of the tasks that you need to do:
|
||||
|
||||
Let's start with the task #1 Getting additional answers. Think about the description for the {{ app_type }} "{{ name }}" and ask questions that you would like to get cleared before going onto breaking down the user stories.
|
||||
|
||||
{{no_microservices}}
|
||||
|
||||
{{single_question}}
|
||||
|
||||
@@ -12,7 +12,7 @@ from logger.logger import logger
|
||||
|
||||
|
||||
def ask_for_app_type():
|
||||
return 'app'
|
||||
return 'Web App'
|
||||
answer = styled_select(
|
||||
"What type of app do you want to build?",
|
||||
choices=common.APP_TYPES
|
||||
@@ -75,7 +75,7 @@ def get_additional_info_from_openai(project, messages):
|
||||
|
||||
if response is not None:
|
||||
if response['text'].strip() == END_RESPONSE:
|
||||
print(response['text'])
|
||||
print(response['text'] + '\n')
|
||||
return messages
|
||||
|
||||
# Ask the question to the user
|
||||
@@ -109,9 +109,7 @@ def get_additional_info_from_user(project, messages, role):
|
||||
if answer.lower() == '':
|
||||
break
|
||||
response = create_gpt_chat_completion(
|
||||
generate_messages_from_custom_conversation(role, [get_prompt('utils/update.prompt'), message, answer],
|
||||
'user'),
|
||||
'additional_info')
|
||||
generate_messages_from_custom_conversation(role, [get_prompt('utils/update.prompt'), message, answer], 'user'), 'additional_info')
|
||||
|
||||
message = response
|
||||
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
You are an experienced software architect. Your expertise is in creating an architecture for an MVP (minimum viable products) for web apps that can be developed as fast as possible by using as many ready-made technologies as possible. The technologies that you prefer using when other technologies are not explicitly specified are:
|
||||
You are an experienced software architect. Your expertise is in creating an architecture for an MVP (minimum viable products) for {{ app_type }}s that can be developed as fast as possible by using as many ready-made technologies as possible. The technologies that you prefer using when other technologies are not explicitly specified are:
|
||||
**Scripts**: you prefer using Node.js for writing scripts that are meant to be ran just with the CLI.
|
||||
|
||||
**Backend**: you prefer using Node.js with Mongo database if not explicitely specified otherwise. When you're using Mongo, you always use Mongoose and when you're using Postgresql, you always use PeeWee as an ORM.
|
||||
|
||||
@@ -1,9 +1,11 @@
|
||||
import hashlib
|
||||
import os
|
||||
import re
|
||||
import sys
|
||||
import uuid
|
||||
|
||||
from getpass import getuser
|
||||
from termcolor import colored
|
||||
|
||||
from database.database import get_app
|
||||
from database.database import get_app, get_app_by_user_workspace
|
||||
|
||||
|
||||
def get_arguments():
|
||||
@@ -22,26 +24,41 @@ def get_arguments():
|
||||
else:
|
||||
arguments[arg] = True
|
||||
|
||||
if 'user_id' not in arguments:
|
||||
arguments['user_id'] = username_to_uuid(getuser())
|
||||
|
||||
app = None
|
||||
if 'workspace' in arguments:
|
||||
app = get_app_by_user_workspace(arguments['user_id'], arguments['workspace'])
|
||||
if app is not None:
|
||||
arguments['app_id'] = app.id
|
||||
else:
|
||||
arguments['workspace'] = None
|
||||
|
||||
if 'app_id' in arguments:
|
||||
try:
|
||||
app = get_app(arguments['app_id'])
|
||||
arguments['user_id'] = str(app.user.id)
|
||||
if app is None:
|
||||
app = get_app(arguments['app_id'])
|
||||
|
||||
arguments['app_type'] = app.app_type
|
||||
arguments['name'] = app.name
|
||||
# Add any other fields from the App model you wish to include
|
||||
|
||||
print(colored('\n------------------ LOADING PROJECT ----------------------', 'green', attrs=['bold']))
|
||||
print(colored(f'{app.name} (app_id={arguments["app_id"]})', 'green', attrs=['bold']))
|
||||
print(colored('--------------------------------------------------------------\n', 'green', attrs=['bold']))
|
||||
except ValueError as e:
|
||||
print(e)
|
||||
# Handle the error as needed, possibly exiting the script
|
||||
else:
|
||||
arguments['app_id'] = str(uuid.uuid4())
|
||||
|
||||
if 'user_id' not in arguments:
|
||||
arguments['user_id'] = str(uuid.uuid4())
|
||||
print(colored('\n------------------ STARTING NEW PROJECT ----------------------', 'green', attrs=['bold']))
|
||||
print("If you wish to continue with this project in future run:")
|
||||
print(colored(f'python {sys.argv[0]} app_id={arguments["app_id"]}', 'green', attrs=['bold']))
|
||||
print(colored('--------------------------------------------------------------\n', 'green', attrs=['bold']))
|
||||
|
||||
if 'email' not in arguments:
|
||||
# todo change email so its not uuid4 but make sure to fix storing of development steps where
|
||||
# 1 user can have multiple apps. In that case each app should have its own development steps
|
||||
arguments['email'] = str(uuid.uuid4())
|
||||
arguments['email'] = get_email()
|
||||
|
||||
if 'password' not in arguments:
|
||||
arguments['password'] = 'password'
|
||||
@@ -49,6 +66,31 @@ def get_arguments():
|
||||
if 'step' not in arguments:
|
||||
arguments['step'] = None
|
||||
|
||||
print(f"If you wish to continue with this project in future run:")
|
||||
print(colored(f'python main.py app_id={arguments["app_id"]}', 'yellow', attrs=['bold']))
|
||||
return arguments
|
||||
|
||||
|
||||
def get_email():
|
||||
# Attempt to get email from .gitconfig
|
||||
gitconfig_path = os.path.expanduser('~/.gitconfig')
|
||||
|
||||
if os.path.exists(gitconfig_path):
|
||||
with open(gitconfig_path, 'r') as file:
|
||||
content = file.read()
|
||||
|
||||
# Use regex to search for email address
|
||||
email_match = re.search(r'email\s*=\s*([\w\.-]+@[\w\.-]+)', content)
|
||||
|
||||
if email_match:
|
||||
return email_match.group(1)
|
||||
|
||||
# If not found, return a UUID
|
||||
# todo change email so its not uuid4 but make sure to fix storing of development steps where
|
||||
# 1 user can have multiple apps. In that case each app should have its own development steps
|
||||
return str(uuid.uuid4())
|
||||
|
||||
|
||||
# TODO can we make BaseModel.id a CharField with default=uuid4?
|
||||
def username_to_uuid(username):
|
||||
sha1 = hashlib.sha1(username.encode()).hexdigest()
|
||||
uuid_str = "{}-{}-{}-{}-{}".format(sha1[:8], sha1[8:12], sha1[12:16], sha1[16:20], sha1[20:32])
|
||||
return str(uuid.UUID(uuid_str))
|
||||
|
||||
51
pilot/utils/exit.py
Normal file
51
pilot/utils/exit.py
Normal file
@@ -0,0 +1,51 @@
|
||||
# exit.py
|
||||
import os
|
||||
import hashlib
|
||||
import requests
|
||||
|
||||
from utils.questionary import get_user_feedback
|
||||
|
||||
|
||||
def send_telemetry(path_id):
|
||||
# Prepare the telemetry data
|
||||
telemetry_data = {
|
||||
"pathId": path_id,
|
||||
"event": "pilot-exit"
|
||||
}
|
||||
|
||||
try:
|
||||
response = requests.post("https://api.pythagora.io/telemetry", json=telemetry_data)
|
||||
response.raise_for_status()
|
||||
except requests.RequestException as err:
|
||||
print(f"Failed to send telemetry data: {err}")
|
||||
|
||||
|
||||
def send_feedback(feedback, path_id):
|
||||
"""Send the collected feedback to the endpoint."""
|
||||
# Prepare the feedback data (you can adjust the structure as per your backend needs)
|
||||
feedback_data = {
|
||||
"pathId": path_id,
|
||||
"data": feedback,
|
||||
"event": "pilot-feedback"
|
||||
}
|
||||
|
||||
try:
|
||||
response = requests.post("https://api.pythagora.io/telemetry", json=feedback_data)
|
||||
response.raise_for_status()
|
||||
except requests.RequestException as err:
|
||||
print(f"Failed to send feedback data: {err}")
|
||||
|
||||
|
||||
def get_path_id():
|
||||
# Calculate the SHA-256 hash of the installation directory
|
||||
installation_directory = os.path.abspath(os.path.join(os.getcwd(), ".."))
|
||||
return hashlib.sha256(installation_directory.encode()).hexdigest()
|
||||
|
||||
|
||||
def exit_gpt_pilot():
|
||||
path_id = get_path_id()
|
||||
send_telemetry(path_id)
|
||||
|
||||
feedback = get_user_feedback()
|
||||
if feedback: # only send if user provided feedback
|
||||
send_feedback(feedback, path_id)
|
||||
@@ -1,6 +1,6 @@
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
from database.database import save_user_app
|
||||
|
||||
def get_parent_folder(folder_name):
|
||||
current_path = Path(os.path.abspath(__file__)) # get the path of the current script
|
||||
@@ -11,10 +11,18 @@ def get_parent_folder(folder_name):
|
||||
return current_path.parent
|
||||
|
||||
|
||||
def setup_workspace(project_name):
|
||||
def setup_workspace(args):
|
||||
if args['workspace'] is not None:
|
||||
try:
|
||||
save_user_app(args['user_id'], args['app_id'], args['workspace'])
|
||||
except Exception as e:
|
||||
print(str(e))
|
||||
|
||||
return args['workspace']
|
||||
|
||||
root = get_parent_folder('pilot')
|
||||
create_directory(root, 'workspace')
|
||||
project_path = create_directory(os.path.join(root, 'workspace'), project_name)
|
||||
project_path = create_directory(os.path.join(root, 'workspace'), args['name'])
|
||||
create_directory(project_path, 'tests')
|
||||
return project_path
|
||||
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
import re
|
||||
import requests
|
||||
import os
|
||||
import sys
|
||||
import time
|
||||
import json
|
||||
import tiktoken
|
||||
import questionary
|
||||
@@ -46,8 +48,11 @@ def get_tokens_in_messages(messages: List[str]) -> int:
|
||||
tokenized_messages = [tokenizer.encode(message['content']) for message in messages]
|
||||
return sum(len(tokens) for tokens in tokenized_messages)
|
||||
|
||||
#get endpoint and model name from .ENV file
|
||||
model = os.getenv('MODEL_NAME')
|
||||
endpoint = os.getenv('ENDPOINT')
|
||||
|
||||
def num_tokens_from_functions(functions, model="gpt-4"):
|
||||
def num_tokens_from_functions(functions, model=model):
|
||||
"""Return the number of tokens used by a list of functions."""
|
||||
encoding = tiktoken.get_encoding("cl100k_base")
|
||||
|
||||
@@ -74,8 +79,8 @@ def num_tokens_from_functions(functions, model="gpt-4"):
|
||||
for o in v['enum']:
|
||||
function_tokens += 3
|
||||
function_tokens += len(encoding.encode(o))
|
||||
else:
|
||||
print(f"Warning: not supported field {field}")
|
||||
# else:
|
||||
# print(f"Warning: not supported field {field}")
|
||||
function_tokens += 11
|
||||
|
||||
num_tokens += function_tokens
|
||||
@@ -86,17 +91,10 @@ def num_tokens_from_functions(functions, model="gpt-4"):
|
||||
|
||||
def create_gpt_chat_completion(messages: List[dict], req_type, min_tokens=MIN_TOKENS_FOR_GPT_RESPONSE,
|
||||
function_calls=None):
|
||||
tokens_in_messages = round(get_tokens_in_messages(messages) * 1.2) # add 20% to account for not 100% accuracy
|
||||
if function_calls is not None:
|
||||
tokens_in_messages += round(
|
||||
num_tokens_from_functions(function_calls['definitions']) * 1.2) # add 20% to account for not 100% accuracy
|
||||
if tokens_in_messages + min_tokens > MAX_GPT_MODEL_TOKENS:
|
||||
raise ValueError(f'Too many tokens in messages: {tokens_in_messages}. Please try a different test.')
|
||||
|
||||
gpt_data = {
|
||||
'model': 'gpt-4',
|
||||
'model': os.getenv('OPENAI_MODEL', 'gpt-4'),
|
||||
'n': 1,
|
||||
'max_tokens': min(4096, MAX_GPT_MODEL_TOKENS - tokens_in_messages),
|
||||
'max_tokens': 4096,
|
||||
'temperature': 1,
|
||||
'top_p': 1,
|
||||
'presence_penalty': 0,
|
||||
@@ -116,9 +114,14 @@ def create_gpt_chat_completion(messages: List[dict], req_type, min_tokens=MIN_TO
|
||||
response = stream_gpt_completion(gpt_data, req_type)
|
||||
return response
|
||||
except Exception as e:
|
||||
print(
|
||||
'The request to OpenAI API failed. Here is the error message:')
|
||||
print(e)
|
||||
error_message = str(e)
|
||||
|
||||
# Check if the error message is related to token limit
|
||||
if "context_length_exceeded" in error_message.lower():
|
||||
raise Exception('Too many tokens in the request. Please try to continue the project with some previous development step.')
|
||||
else:
|
||||
print('The request to OpenAI API failed. Here is the error message:')
|
||||
print(e)
|
||||
|
||||
|
||||
def delete_last_n_lines(n):
|
||||
@@ -140,8 +143,23 @@ def retry_on_exception(func):
|
||||
try:
|
||||
return func(*args, **kwargs)
|
||||
except Exception as e:
|
||||
print(colored(f'There was a problem with request to openai API:', 'red'))
|
||||
print(str(e))
|
||||
# Convert exception to string
|
||||
err_str = str(e)
|
||||
|
||||
# If the specific error "context_length_exceeded" is present, simply return without retry
|
||||
if "context_length_exceeded" in err_str:
|
||||
raise Exception("context_length_exceeded")
|
||||
if "rate_limit_exceeded" in err_str:
|
||||
# Extracting the duration from the error string
|
||||
match = re.search(r"Please try again in (\d+)ms.", err_str)
|
||||
if match:
|
||||
wait_duration = int(match.group(1)) / 1000
|
||||
time.sleep(wait_duration)
|
||||
continue
|
||||
|
||||
print(colored('There was a problem with request to openai API:', 'red'))
|
||||
print(err_str)
|
||||
|
||||
user_message = questionary.text(
|
||||
"Do you want to try make the same request again? If yes, just press ENTER. Otherwise, type 'no'.",
|
||||
style=questionary.Style([
|
||||
@@ -170,14 +188,29 @@ def stream_gpt_completion(data, req_type):
|
||||
return result_data
|
||||
|
||||
# spinner = spinner_start(colored("Waiting for OpenAI API response...", 'yellow'))
|
||||
print(colored("Waiting for OpenAI API response...", 'yellow'))
|
||||
api_key = os.getenv("OPENAI_API_KEY")
|
||||
# print(colored("Stream response from OpenAI:", 'yellow'))
|
||||
|
||||
logger.info(f'Request data: {data}')
|
||||
|
||||
# Check if the ENDPOINT is AZURE
|
||||
if endpoint == 'AZURE':
|
||||
# If yes, get the AZURE_ENDPOINT from .ENV file
|
||||
endpoint_url = os.getenv('AZURE_ENDPOINT') + '/openai/deployments/' + model + '/chat/completions?api-version=2023-05-15'
|
||||
headers = {
|
||||
'Content-Type': 'application/json',
|
||||
'api-key': os.getenv('AZURE_API_KEY')
|
||||
}
|
||||
else:
|
||||
# If not, send the request to the OpenAI endpoint
|
||||
headers = {
|
||||
'Content-Type': 'application/json',
|
||||
'Authorization': 'Bearer ' + os.getenv("OPENAI_API_KEY")
|
||||
}
|
||||
endpoint_url = 'https://api.openai.com/v1/chat/completions'
|
||||
|
||||
response = requests.post(
|
||||
'https://api.openai.com/v1/chat/completions',
|
||||
headers={'Content-Type': 'application/json', 'Authorization': 'Bearer ' + api_key},
|
||||
endpoint_url,
|
||||
headers=headers,
|
||||
json=data,
|
||||
stream=True
|
||||
)
|
||||
@@ -212,7 +245,7 @@ def stream_gpt_completion(data, req_type):
|
||||
|
||||
if json_line['choices'][0]['finish_reason'] == 'function_call':
|
||||
function_calls['arguments'] = load_data_to_json(function_calls['arguments'])
|
||||
return return_result({'function_calls': function_calls}, lines_printed);
|
||||
return return_result({'function_calls': function_calls}, lines_printed)
|
||||
|
||||
json_line = json_line['choices'][0]['delta']
|
||||
|
||||
|
||||
@@ -33,4 +33,14 @@ def styled_text(project, question):
|
||||
}
|
||||
response = questionary.text(question, **config).unsafe_ask() # .ask() is included here
|
||||
user_input = save_user_input(project, question, response)
|
||||
|
||||
print('\n\n', end='')
|
||||
|
||||
return response
|
||||
|
||||
|
||||
def get_user_feedback():
|
||||
config = {
|
||||
'style': custom_style,
|
||||
}
|
||||
return questionary.text("How did GPT Pilot do? Were you able to create any app that works? Please write any feedback you have or just press ENTER to exit: ", **config).unsafe_ask()
|
||||
|
||||
40
pilot/utils/test_arguments.py
Normal file
40
pilot/utils/test_arguments.py
Normal file
@@ -0,0 +1,40 @@
|
||||
import pytest
|
||||
from unittest.mock import patch, mock_open
|
||||
import uuid
|
||||
from .arguments import get_email, username_to_uuid
|
||||
|
||||
|
||||
def test_email_found_in_gitconfig():
|
||||
mock_file_content = """
|
||||
[user]
|
||||
name = test_user
|
||||
email = test@example.com
|
||||
"""
|
||||
with patch('os.path.exists', return_value=True):
|
||||
with patch('builtins.open', mock_open(read_data=mock_file_content)):
|
||||
assert get_email() == "test@example.com"
|
||||
|
||||
|
||||
def test_email_not_found_in_gitconfig():
|
||||
mock_file_content = """
|
||||
[user]
|
||||
name = test_user
|
||||
"""
|
||||
mock_uuid = "12345678-1234-5678-1234-567812345678"
|
||||
|
||||
with patch('os.path.exists', return_value=True):
|
||||
with patch('builtins.open', mock_open(read_data=mock_file_content)):
|
||||
with patch.object(uuid, "uuid4", return_value=mock_uuid):
|
||||
assert get_email() == mock_uuid
|
||||
|
||||
|
||||
def test_gitconfig_not_present():
|
||||
mock_uuid = "12345678-1234-5678-1234-567812345678"
|
||||
|
||||
with patch('os.path.exists', return_value=False):
|
||||
with patch.object(uuid, "uuid4", return_value=mock_uuid):
|
||||
assert get_email() == mock_uuid
|
||||
|
||||
|
||||
def test_username_to_uuid():
|
||||
assert username_to_uuid("test_user") == "31676025-316f-b555-e0bf-a12f0bcfd0ea"
|
||||
26
pilot/utils/test_files.py
Normal file
26
pilot/utils/test_files.py
Normal file
@@ -0,0 +1,26 @@
|
||||
import pytest
|
||||
from .files import setup_workspace
|
||||
|
||||
|
||||
def test_setup_workspace_with_existing_workspace():
|
||||
args = {'workspace': 'some_directory', 'name': 'sample'}
|
||||
result = setup_workspace(args)
|
||||
assert result == 'some_directory'
|
||||
|
||||
|
||||
def mocked_create_directory(path, exist_ok=True):
|
||||
return
|
||||
|
||||
|
||||
def mocked_abspath(file):
|
||||
return "/root_path/pilot/helpers"
|
||||
|
||||
|
||||
def test_setup_workspace_without_existing_workspace(monkeypatch):
|
||||
args = {'workspace': None, 'name': 'project_name'}
|
||||
|
||||
monkeypatch.setattr('os.path.abspath', mocked_abspath)
|
||||
monkeypatch.setattr('os.makedirs', mocked_create_directory)
|
||||
|
||||
result = setup_workspace(args)
|
||||
assert result.replace('\\', '/') == "/root_path/workspace/project_name"
|
||||
@@ -135,6 +135,7 @@ def hash_data(data):
|
||||
serialized_data = json.dumps(replace_functions(data), sort_keys=True).encode('utf-8')
|
||||
return hashlib.sha256(serialized_data).hexdigest()
|
||||
|
||||
|
||||
def replace_functions(obj):
|
||||
if isinstance(obj, dict):
|
||||
return {k: replace_functions(v) for k, v in obj.items()}
|
||||
@@ -145,12 +146,14 @@ def replace_functions(obj):
|
||||
else:
|
||||
return obj
|
||||
|
||||
|
||||
def fix_json(s):
|
||||
s = s.replace('True', 'true')
|
||||
s = s.replace('False', 'false')
|
||||
# s = s.replace('`', '"')
|
||||
return fix_json_newlines(s)
|
||||
|
||||
|
||||
def fix_json_newlines(s):
|
||||
pattern = r'("(?:\\\\n|\\.|[^"\\])*")'
|
||||
|
||||
@@ -159,6 +162,7 @@ def fix_json_newlines(s):
|
||||
|
||||
return re.sub(pattern, replace_newlines, s)
|
||||
|
||||
|
||||
def clean_filename(filename):
|
||||
# Remove invalid characters
|
||||
cleaned_filename = re.sub(r'[<>:"/\\|?*]', '', filename)
|
||||
|
||||
Reference in New Issue
Block a user